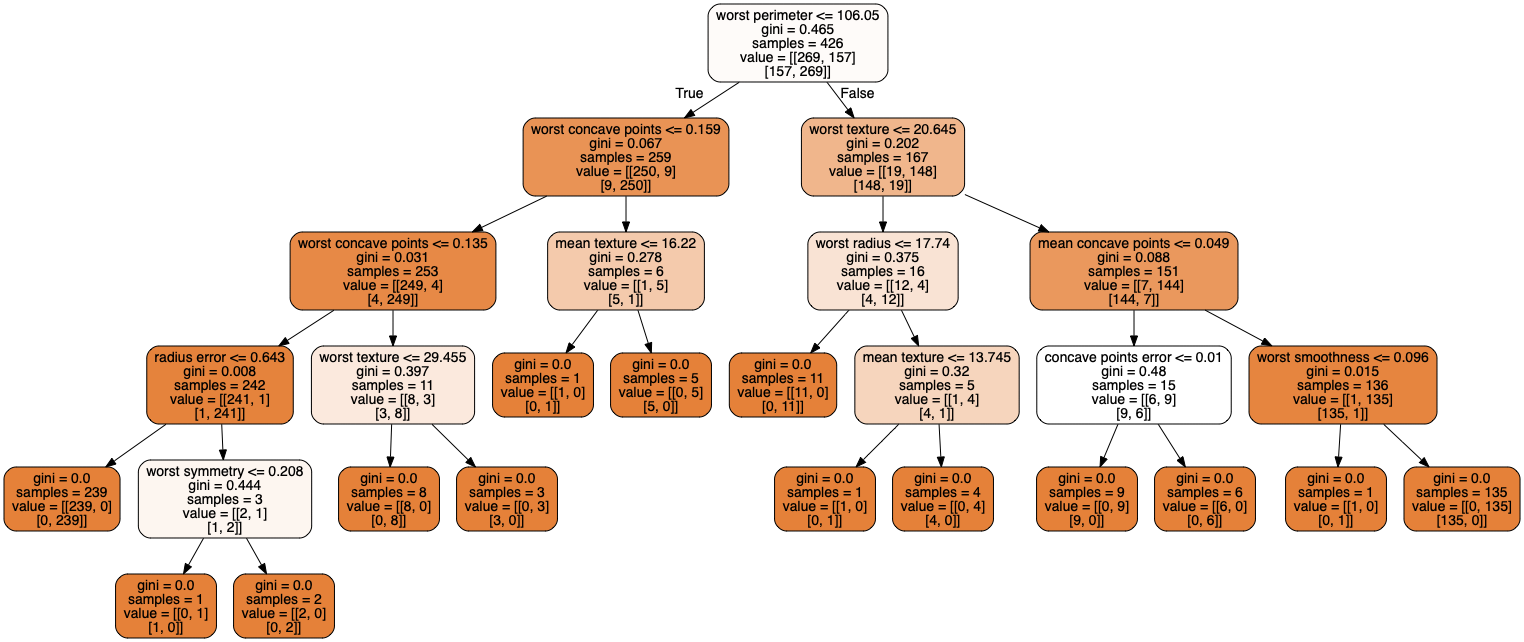
We start here with the most basic algorithm, the so-called decision tree. With this basic algorithm we can in turn build more complex networks, spanning from homogeneous and heterogenous forests (bagging, random forests and more) to one of the most popular supervised algorithms nowadays, the extreme gradient boosting, or just XGBoost. But let us start with the simplest possible ingredient.
Decision trees are supervised learning algorithms used for both, classification and regression tasks.
The main idea of decision trees is to find those descriptive features which contain the most information regarding the target feature and then split the dataset along the values of these features such that the target feature values for the resulting underlying datasets are as pure as possible.
The descriptive features which reproduce best the target/output features are normally said to be the most informative ones. The process of finding the most informative feature is done until we accomplish a stopping criteria where we then finally end up in so called leaf nodes.
A decision tree is typically divided into a root node, the interior nodes, and the final leaf nodes or just leaves. These entities are then connected by so-called branches.
The leaf nodes contain the predictions we will make for new query instances presented to our trained model. This is possible since the model has learned the underlying structure of the training data and hence can, given some assumptions, make predictions about the target feature value (class) of unseen query instances.
This tree was produced using the Wisconsin cancer data (discussed here as well, see code examples below) using Scikit-Learn's decision tree classifier. Here we have used the so-called gini index (see below) to split the various branches.
The overarching approach to decision trees is a top-down approach.
In simplified terms, the process of training a decision tree and predicting the target features of query instances is as follows:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
steps=250
distance=0
x=0
distance_list=[]
steps_list=[]
while x<steps:
distance+=np.random.randint(-1,2)
distance_list.append(distance)
x+=1
steps_list.append(x)
plt.plot(steps_list,distance_list, color='green', label="Random Walk Data")
steps_list=np.asarray(steps_list)
distance_list=np.asarray(distance_list)
X=steps_list[:,np.newaxis]
#Polynomial fits
#Degree 2
poly_features=PolynomialFeatures(degree=2, include_bias=False)
X_poly=poly_features.fit_transform(X)
lin_reg=LinearRegression()
poly_fit=lin_reg.fit(X_poly,distance_list)
b=lin_reg.coef_
c=lin_reg.intercept_
print ("2nd degree coefficients:")
print ("zero power: ",c)
print ("first power: ", b[0])
print ("second power: ",b[1])
z = np.arange(0, steps, .01)
z_mod=b[1]*z**2+b[0]*z+c
fit_mod=b[1]*X**2+b[0]*X+c
plt.plot(z, z_mod, color='r', label="2nd Degree Fit")
plt.title("Polynomial Regression")
plt.xlabel("Steps")
plt.ylabel("Distance")
#Degree 10
poly_features10=PolynomialFeatures(degree=10, include_bias=False)
X_poly10=poly_features10.fit_transform(X)
poly_fit10=lin_reg.fit(X_poly10,distance_list)
y_plot=poly_fit10.predict(X_poly10)
plt.plot(X, y_plot, color='black', label="10th Degree Fit")
plt.legend()
plt.show()
#Decision Tree Regression
from sklearn.tree import DecisionTreeRegressor
regr_1=DecisionTreeRegressor(max_depth=2)
regr_2=DecisionTreeRegressor(max_depth=5)
regr_3=DecisionTreeRegressor(max_depth=7)
regr_1.fit(X, distance_list)
regr_2.fit(X, distance_list)
regr_3.fit(X, distance_list)
X_test = np.arange(0.0, steps, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
y_3=regr_3.predict(X_test)
# Plot the results
plt.figure()
plt.scatter(X, distance_list, s=2.5, c="black", label="data")
plt.plot(X_test, y_1, color="red",
label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="green", label="max_depth=5", linewidth=2)
plt.plot(X_test, y_3, color="m", label="max_depth=7", linewidth=2)
plt.xlabel("Data")
plt.ylabel("Darget")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
There are mainly two steps
where \( \overline{y}_{R_j} \) is the mean response for the training observations within box \( j \).
Unfortunately, it is computationally infeasible to consider every possible partition of the feature space into \( J \) boxes. The common strategy is to take a top-down approach
The approach is top-down because it begins at the top of the tree (all observations belong to a single region) and then successively splits the predictor space; each split is indicated via two new branches further down on the tree. It is greedy because at each step of the tree-building process, the best split is made at that particular step, rather than looking ahead and picking a split that will lead to a better tree in some future step.
In order to implement the recursive binary splitting we start by selecting the predictor \( x_j \) and a cutpoint \( s \) that splits the predictor space into two regions \( R_1 \) and \( R_2 \) $$ \left\{X\vert x_j < s\right\}, $$ and $$ \left\{X\vert x_j \geq s\right\}, $$ so that we obtain the lowest MSE, that is $$ \sum_{i:x_i\in R_j}(y_i-\overline{y}_{R_1})^2+\sum_{i:x_i\in R_2}(y_i-\overline{y}_{R_2})^2, $$
which we want to minimize by considering all predictors \( x_1,x_2,\dots,x_p \). We consider also all possible values of \( s \) for each predictor. These values could be determined by randomly assigned numbers or by starting at the midpoint and then proceed till we find an optimal value.
For any \( j \) and \( s \), we define the pair of half-planes where \( \overline{y}_{R_1} \) is the mean response for the training observations in \( R_1(j,s) \), and \( \overline{y}_{R_2} \) is the mean response for the training observations in \( R_2(j,s) \).
Finding the values of \( j \) and \( s \) that minimize the above equation can be done quite quickly, especially when the number of features \( p \) is not too large.
Next, we repeat the process, looking for the best predictor and best cutpoint in order to split the data further so as to minimize the MSE within each of the resulting regions. However, this time, instead of splitting the entire predictor space, we split one of the two previously identified regions. We now have three regions. Again, we look to split one of these three regions further, so as to minimize the MSE. The process continues until a stopping criterion is reached; for instance, we may continue until no region contains more than five observations.
The above procedure is rather straightforward, but leads often to overfitting and unnecessarily large and complicated trees. The basic idea is to grow a large tree \( T_0 \) and then prune it back in order to obtain a subtree. A smaller tree with fewer splits (fewer regions) can lead to smaller variance and better interpretation at the cost of a little more bias.
The so-called Cost complexity pruning algorithm gives us a way to do just this. Rather than considering every possible subtree, we consider a sequence of trees indexed by a nonnegative tuning parameter \( \alpha \).
The tuning parameter \( \alpha \) controls a trade-off between the subtree’s com- plexity and its fit to the training data. When \( \alpha = 0 \), then the subtree \( T \) will simply equal \( T_0 \), because then the above equation just measures the training error. However, as \( \alpha \) increases, there is a price to pay for having a tree with many terminal nodes. The above equation will tend to be minimized for a smaller subtree.
It turns out that as we increase \( \alpha \) from zero branches get pruned from the tree in a nested and predictable fashion, so obtaining the whole sequence of subtrees as a function of \( \alpha \) is easy. We can select a value of \( \alpha \) using a validation set or using cross-validation. We then return to the full data set and obtain the subtree corresponding to \( \alpha \).
A classification tree is very similar to a regression tree, except that it is used to predict a qualitative response rather than a quantitative one. Recall that for a regression tree, the predicted response for an observation is given by the mean response of the training observations that belong to the same terminal node. In contrast, for a classification tree, we predict that each observation belongs to the most commonly occurring class of training observations in the region to which it belongs. In interpreting the results of a classification tree, we are often interested not only in the class prediction corresponding to a particular terminal node region, but also in the class proportions among the training observations that fall into that region.
The task of growing a classification tree is quite similar to the task of growing a regression tree. Just as in the regression setting, we use recursive binary splitting to grow a classification tree. However, in the classification setting, the MSE cannot be used as a criterion for making the binary splits. A natural alternative to MSE is the classification error rate. Since we plan to assign an observation in a given region to the most commonly occurring error rate class of training observations in that region, the classification error rate is simply the fraction of the training observations in that region that do not belong to the most common class.
When building a classification tree, either the Gini index or the entropy are typically used to evaluate the quality of a particular split, since these two approaches are more sensitive to node purity than is the classification error rate.
If our targets are the outcome of a classification process that takes for example \( k=1,2,\dots,K \) values, the only thing we need to think of is to set up the splitting criteria for each node.
We define a PDF \( p_{mk} \) that represents the number of observations of a class \( k \) in a region \( R_m \) with \( N_m \) observations. We represent this likelihood function in terms of the proportion \( I(y_i=k) \) of observations of this class in the region \( R_m \) as $$ p_{mk} = \frac{1}{N_m}\sum_{x_i\in R_m}I(y_i=k). $$
We let \( p_{mk} \) represent the majority class of observations in region \( m \). The three most common ways of splitting a node are given by
import os
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.tree import export_graphviz
from IPython.display import Image
from pydot import graph_from_dot_data
import pandas as pd
import numpy as np
cancer = load_breast_cancer()
X = pd.DataFrame(cancer.data, columns=cancer.feature_names)
print(X)
y = pd.Categorical.from_codes(cancer.target, cancer.target_names)
y = pd.get_dummies(y)
print(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
tree_clf = DecisionTreeClassifier(max_depth=5)
tree_clf.fit(X_train, y_train)
export_graphviz(
tree_clf,
out_file="DataFiles/cancer.dot",
feature_names=cancer.feature_names,
class_names=cancer.target_names,
rounded=True,
filled=True
)
cmd = 'dot -Tpng DataFiles/cancer.dot -o DataFiles/cancer.png'
os.system(cmd)
# Common imports
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_moons
from sklearn.tree import export_graphviz
from pydot import graph_from_dot_data
import pandas as pd
import os
np.random.seed(42)
X, y = make_moons(n_samples=100, noise=0.25, random_state=53)
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
tree_clf = DecisionTreeClassifier(max_depth=5)
tree_clf.fit(X_train, y_train)
export_graphviz(
tree_clf,
out_file="DataFiles/moons.dot",
rounded=True,
filled=True
)
cmd = 'dot -Tpng DataFiles/moons.dot -o DataFiles/moons.png'
os.system(cmd)
Two algorithms stand out in the set up of decision trees:
For classification, the CART algorithm splits the data set in two subsets using a single feature \( k \) and a threshold \( t_k \). This could be for example a threshold set by a number below a certain circumference of a malign tumor.
How do we find these two quantities? We search for the pair \( (k,t_k) \) that produces the purest subset using for example the gini factor \( G \). The cost function it tries to minimize is then $$ C(k,t_k) = \frac{m_{\mathrm{left}}}{m}G_{\mathrm{left}}+ \frac{m_{\mathrm{right}}}{m}G_{\mathrm{right}}, $$ where \( G_{\mathrm{left/right}} \) measures the impurity of the left/right subset and \( m_{\mathrm{left/right}} \) is the number of instances in the left/right subset
Once it has successfully split the training set in two, it splits the subsets using the same logic, then the subsubsets and so on, recursively. It stops recursing once it reaches the maximum depth (defined by the \( max\_depth \) hyperparameter), or if it cannot find a split that will reduce impurity. A few other hyperparameters control additional stopping conditions such as the \( min\_samples\_split \), \( min\_samples\_leaf \), \( min\_weight\_fraction\_leaf \), and \( max\_leaf\_nodes \).
The CART algorithm for regression works is similar to the one for classification except that instead of trying to split the training set in a way that minimizes say the gini or entropy impurity, it now tries to split the training set in a way that minimizes our well-known mean-squared error (MSE). The cost function is now $$ C(k,t_k) = \frac{m_{\mathrm{left}}}{m}\mathrm{MSE}_{\mathrm{left}}+ \frac{m_{\mathrm{right}}}{m}\mathrm{MSE}_{\mathrm{right}}. $$ Here the MSE for a specific node is defined as $$ \mathrm{MSE}_{\mathrm{node}}=\frac{1}{m_\mathrm{node}}\sum_{i\in \mathrm{node}}(\overline{y}_{\mathrm{node}}-y_i)^2, $$ with $$ \overline{y}_{\mathrm{node}}=\frac{1}{m_\mathrm{node}}\sum_{i\in \mathrm{node}}y_i, $$ the mean value of all observations in a specific node.
Without any regularization, the regression task for decision trees, just like for classification tasks, is prone to overfitting.
The example we will look at is a classical one in many Machine Learning applications. Based on various meteorological features, we have several so-called attributes which decide whether we at the end will do some outdoor activity like skiing, going for a bike ride etc etc. The table here contains the feautures outlook, temperature, humidity and wind. The target or output is whether we ride (True=1) or whether we do something else that day (False=0). The attributes for each feature are then sunny, overcast and rain for the outlook, hot, cold and mild for temperature, high and normal for humidity and weak and strong for wind.
The table here summarizes the various attributes and
| Day | Outlook | Temperature | Humidity | Wind | Ride |
|---|---|---|---|---|---|
| 1 | Sunny | Hot | High | Weak | 0 |
| 2 | Sunny | Hot | High | Strong | 1 |
| 3 | Overcast | Hot | High | Weak | 1 |
| 4 | Rain | Mild | High | Weak | 1 |
| 5 | Rain | Cool | Normal | Weak | 1 |
| 6 | Rain | Cool | Normal | Strong | 0 |
| 7 | Overcast | Cool | Normal | Strong | 1 |
| 8 | Sunny | Mild | High | Weak | 0 |
| 9 | Sunny | Cool | Normal | Weak | 1 |
| 10 | Rain | Mild | Normal | Weak | 1 |
| 11 | Sunny | Mild | Normal | Strong | 1 |
| 12 | Overcast | Mild | High | Strong | 1 |
| 13 | Overcast | Hot | Normal | Weak | 1 |
| 14 | Rain | Mild | High | Strong | 0 |
# Common imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import export_graphviz
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from IPython.display import Image
from pydot import graph_from_dot_data
import os
# Where to save the figures and data files
PROJECT_ROOT_DIR = "Results"
FIGURE_ID = "Results/FigureFiles"
DATA_ID = "DataFiles/"
if not os.path.exists(PROJECT_ROOT_DIR):
os.mkdir(PROJECT_ROOT_DIR)
if not os.path.exists(FIGURE_ID):
os.makedirs(FIGURE_ID)
if not os.path.exists(DATA_ID):
os.makedirs(DATA_ID)
def image_path(fig_id):
return os.path.join(FIGURE_ID, fig_id)
def data_path(dat_id):
return os.path.join(DATA_ID, dat_id)
def save_fig(fig_id):
plt.savefig(image_path(fig_id) + ".png", format='png')
infile = open(data_path("rideclass.csv"),'r')
# Read the experimental data with Pandas
from IPython.display import display
ridedata = pd.read_csv(infile,names = ('Outlook','Temperature','Humidity','Wind','Ride'))
ridedata = pd.DataFrame(ridedata)
# Features and targets
X = ridedata.loc[:, ridedata.columns != 'Ride'].values
y = ridedata.loc[:, ridedata.columns == 'Ride'].values
# Create the encoder.
encoder = OneHotEncoder(handle_unknown="ignore")
# Assume for simplicity all features are categorical.
encoder.fit(X)
# Apply the encoder.
X = encoder.transform(X)
print(X)
# Then do a Classification tree
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
print("Train set accuracy with Decision Tree: {:.2f}".format(tree_clf.score(X,y)))
#transfer to a decision tree graph
export_graphviz(
tree_clf,
out_file="DataFiles/ride.dot",
rounded=True,
filled=True
)
cmd = 'dot -Tpng DataFiles/cancer.dot -o DataFiles/cancer.png'
os.system(cmd)
The above functions (gini, entropy and misclassification error) are important components of the so-called CART algorithm. We will discuss this algorithm below after we have discussed the information gain algorithm ID3.
In the example here we have converted all our attributes into numerical values \( 0,1,2 \) etc.
# Split a dataset based on an attribute and an attribute value
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# Calculate the Gini index for a split dataset
def gini_index(groups, classes):
# count all samples at split point
n_instances = float(sum([len(group) for group in groups]))
# sum weighted Gini index for each group
gini = 0.0
for group in groups:
size = float(len(group))
# avoid divide by zero
if size == 0:
continue
score = 0.0
# score the group based on the score for each class
for class_val in classes:
p = [row[-1] for row in group].count(class_val) / size
score += p * p
# weight the group score by its relative size
gini += (1.0 - score) * (size / n_instances)
return gini
# Select the best split point for a dataset
def get_split(dataset):
class_values = list(set(row[-1] for row in dataset))
b_index, b_value, b_score, b_groups = 999, 999, 999, None
for index in range(len(dataset[0])-1):
for row in dataset:
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_values)
print('X%d < %.3f Gini=%.3f' % ((index+1), row[index], gini))
if gini < b_score:
b_index, b_value, b_score, b_groups = index, row[index], gini, groups
return {'index':b_index, 'value':b_value, 'groups':b_groups}
dataset = [[0,0,0,0,0],
[0,0,0,1,1],
[1,0,0,0,1],
[2,1,0,0,1],
[2,2,1,0,1],
[2,2,1,1,0],
[1,2,1,1,1],
[0,1,0,0,0],
[0,2,1,0,1],
[2,1,1,0,1],
[0,1,1,1,1],
[1,1,0,1,1],
[1,0,1,0,1],
[2,1,0,1,0]]
split = get_split(dataset)
print('Split: [X%d < %.3f]' % ((split['index']+1), split['value']))
ID3, learns decision trees by constructing them topdown, beginning with the question which attribute should be tested at the root of the tree?
We would like to select the attribute that is most useful for classifying examples.
What is a good quantitative measure of the worth of an attribute?
Information gain measures how well a given attribute separates the training examples according to their target classification.
The ID3 algorithm uses this information gain measure to select among the candidate attributes at each step while growing the tree.
import re
import math
from collections import deque
# x is examples in training set
# y is set of targets
# label is target attributes
# Node is a class which has properties values, childs, and next
# root is top node in the decision tree
class Node(object):
def __init__(self):
self.value = None
self.next = None
self.childs = None
# Simple class of Decision Tree
# Aimed for who want to learn Decision Tree, so it is not optimized
class DecisionTree(object):
def __init__(self, sample, attributes, labels):
self.sample = sample
self.attributes = attributes
self.labels = labels
self.labelCodes = None
self.labelCodesCount = None
self.initLabelCodes()
# print(self.labelCodes)
self.root = None
self.entropy = self.getEntropy([x for x in range(len(self.labels))])
def initLabelCodes(self):
self.labelCodes = []
self.labelCodesCount = []
for l in self.labels:
if l not in self.labelCodes:
self.labelCodes.append(l)
self.labelCodesCount.append(0)
self.labelCodesCount[self.labelCodes.index(l)] += 1
def getLabelCodeId(self, sampleId):
return self.labelCodes.index(self.labels[sampleId])
def getAttributeValues(self, sampleIds, attributeId):
vals = []
for sid in sampleIds:
val = self.sample[sid][attributeId]
if val not in vals:
vals.append(val)
# print(vals)
return vals
def getEntropy(self, sampleIds):
entropy = 0
labelCount = [0] * len(self.labelCodes)
for sid in sampleIds:
labelCount[self.getLabelCodeId(sid)] += 1
# print("-ge", labelCount)
for lv in labelCount:
# print(lv)
if lv != 0:
entropy += -lv/len(sampleIds) * math.log(lv/len(sampleIds), 2)
else:
entropy += 0
return entropy
def getDominantLabel(self, sampleIds):
labelCodesCount = [0] * len(self.labelCodes)
for sid in sampleIds:
labelCodesCount[self.labelCodes.index(self.labels[sid])] += 1
return self.labelCodes[labelCodesCount.index(max(labelCodesCount))]
def getInformationGain(self, sampleIds, attributeId):
gain = self.getEntropy(sampleIds)
attributeVals = []
attributeValsCount = []
attributeValsIds = []
for sid in sampleIds:
val = self.sample[sid][attributeId]
if val not in attributeVals:
attributeVals.append(val)
attributeValsCount.append(0)
attributeValsIds.append([])
vid = attributeVals.index(val)
attributeValsCount[vid] += 1
attributeValsIds[vid].append(sid)
# print("-gig", self.attributes[attributeId])
for vc, vids in zip(attributeValsCount, attributeValsIds):
# print("-gig", vids)
gain -= vc/len(sampleIds) * self.getEntropy(vids)
return gain
def getAttributeMaxInformationGain(self, sampleIds, attributeIds):
attributesEntropy = [0] * len(attributeIds)
for i, attId in zip(range(len(attributeIds)), attributeIds):
attributesEntropy[i] = self.getInformationGain(sampleIds, attId)
maxId = attributeIds[attributesEntropy.index(max(attributesEntropy))]
return self.attributes[maxId], maxId
def isSingleLabeled(self, sampleIds):
label = self.labels[sampleIds[0]]
for sid in sampleIds:
if self.labels[sid] != label:
return False
return True
def getLabel(self, sampleId):
return self.labels[sampleId]
def id3(self):
sampleIds = [x for x in range(len(self.sample))]
attributeIds = [x for x in range(len(self.attributes))]
self.root = self.id3Recv(sampleIds, attributeIds, self.root)
def id3Recv(self, sampleIds, attributeIds, root):
root = Node() # Initialize current root
if self.isSingleLabeled(sampleIds):
root.value = self.labels[sampleIds[0]]
return root
# print(attributeIds)
if len(attributeIds) == 0:
root.value = self.getDominantLabel(sampleIds)
return root
bestAttrName, bestAttrId = self.getAttributeMaxInformationGain(
sampleIds, attributeIds)
# print(bestAttrName)
root.value = bestAttrName
root.childs = [] # Create list of children
for value in self.getAttributeValues(sampleIds, bestAttrId):
# print(value)
child = Node()
child.value = value
root.childs.append(child) # Append new child node to current
# root
childSampleIds = []
for sid in sampleIds:
if self.sample[sid][bestAttrId] == value:
childSampleIds.append(sid)
if len(childSampleIds) == 0:
child.next = self.getDominantLabel(sampleIds)
else:
# print(bestAttrName, bestAttrId)
# print(attributeIds)
if len(attributeIds) > 0 and bestAttrId in attributeIds:
toRemove = attributeIds.index(bestAttrId)
attributeIds.pop(toRemove)
child.next = self.id3Recv(
childSampleIds, attributeIds, child.next)
return root
def printTree(self):
if self.root:
roots = deque()
roots.append(self.root)
while len(roots) > 0:
root = roots.popleft()
print(root.value)
if root.childs:
for child in root.childs:
print('({})'.format(child.value))
roots.append(child.next)
elif root.next:
print(root.next)
def test():
f = open('DataFiles/rideclass.csv')
attributes = f.readline().split(',')
attributes = attributes[1:len(attributes)-1]
print(attributes)
sample = f.readlines()
f.close()
for i in range(len(sample)):
sample[i] = re.sub('\d+,', '', sample[i])
sample[i] = sample[i].strip().split(',')
labels = []
for s in sample:
labels.append(s.pop())
# print(sample)
# print(labels)
decisionTree = DecisionTree(sample, attributes, labels)
print("System entropy {}".format(decisionTree.entropy))
decisionTree.id3()
decisionTree.printTree()
if __name__ == '__main__':
test()
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
# Load the data
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,cancer.target,random_state=0)
print(X_train.shape)
print(X_test.shape)
# Logistic Regression
logreg = LogisticRegression(solver='lbfgs')
logreg.fit(X_train, y_train)
print("Test set accuracy with Logistic Regression: {:.2f}".format(logreg.score(X_test,y_test)))
# Support vector machine
svm = SVC(gamma='auto', C=100)
svm.fit(X_train, y_train)
print("Test set accuracy with SVM: {:.2f}".format(svm.score(X_test,y_test)))
# Decision Trees
deep_tree_clf = DecisionTreeClassifier(max_depth=None)
deep_tree_clf.fit(X_train, y_train)
print("Test set accuracy with Decision Trees: {:.2f}".format(deep_tree_clf.score(X_test,y_test)))
#now scale the data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Logistic Regression
logreg.fit(X_train_scaled, y_train)
print("Test set accuracy Logistic Regression with scaled data: {:.2f}".format(logreg.score(X_test_scaled,y_test)))
# Support Vector Machine
svm.fit(X_train_scaled, y_train)
print("Test set accuracy SVM with scaled data: {:.2f}".format(logreg.score(X_test_scaled,y_test)))
# Decision Trees
deep_tree_clf.fit(X_train_scaled, y_train)
print("Test set accuracy with Decision Trees and scaled data: {:.2f}".format(deep_tree_clf.score(X_test_scaled,y_test)))
from __future__ import division, print_function, unicode_literals
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
from sklearn.svm import SVC
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_moons
from sklearn.tree import export_graphviz
Xm, ym = make_moons(n_samples=100, noise=0.25, random_state=53)
deep_tree_clf1 = DecisionTreeClassifier(random_state=42)
deep_tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42)
deep_tree_clf1.fit(Xm, ym)
deep_tree_clf2.fit(Xm, ym)
def plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
if plot_training:
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==2], X[:, 1][y==2], "g^", label="Iris-Virginica")
plt.axis(axes)
if iris:
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
if legend:
plt.legend(loc="lower right", fontsize=14)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_decision_boundary(deep_tree_clf1, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("No restrictions", fontsize=16)
plt.subplot(122)
plot_decision_boundary(deep_tree_clf2, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("min_samples_leaf = {}".format(deep_tree_clf2.min_samples_leaf), fontsize=14)
plt.show()
np.random.seed(6)
Xs = np.random.rand(100, 2) - 0.5
ys = (Xs[:, 0] > 0).astype(np.float32) * 2
angle = np.pi/4
rotation_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]])
Xsr = Xs.dot(rotation_matrix)
tree_clf_s = DecisionTreeClassifier(random_state=42)
tree_clf_s.fit(Xs, ys)
tree_clf_sr = DecisionTreeClassifier(random_state=42)
tree_clf_sr.fit(Xsr, ys)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_decision_boundary(tree_clf_s, Xs, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
plt.subplot(122)
plot_decision_boundary(tree_clf_sr, Xsr, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
plt.show()
# Quadratic training set + noise
np.random.seed(42)
m = 200
X = np.random.rand(m, 1)
y = 4 * (X - 0.5) ** 2
y = y + np.random.randn(m, 1) / 10
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg.fit(X, y)
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(random_state=42, max_depth=2)
tree_reg2 = DecisionTreeRegressor(random_state=42, max_depth=3)
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
def plot_regression_predictions(tree_reg, X, y, axes=[0, 1, -0.2, 1], ylabel="$y$"):
x1 = np.linspace(axes[0], axes[1], 500).reshape(-1, 1)
y_pred = tree_reg.predict(x1)
plt.axis(axes)
plt.xlabel("$x_1$", fontsize=18)
if ylabel:
plt.ylabel(ylabel, fontsize=18, rotation=0)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_regression_predictions(tree_reg1, X, y)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2)
plt.text(0.21, 0.65, "Depth=0", fontsize=15)
plt.text(0.01, 0.2, "Depth=1", fontsize=13)
plt.text(0.65, 0.8, "Depth=1", fontsize=13)
plt.legend(loc="upper center", fontsize=18)
plt.title("max_depth=2", fontsize=14)
plt.subplot(122)
plot_regression_predictions(tree_reg2, X, y, ylabel=None)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2)
for split in (0.0458, 0.1298, 0.2873, 0.9040):
plt.plot([split, split], [-0.2, 1], "k:", linewidth=1)
plt.text(0.3, 0.5, "Depth=2", fontsize=13)
plt.title("max_depth=3", fontsize=14)
plt.show()
tree_reg1 = DecisionTreeRegressor(random_state=42)
tree_reg2 = DecisionTreeRegressor(random_state=42, min_samples_leaf=10)
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred1 = tree_reg1.predict(x1)
y_pred2 = tree_reg2.predict(x1)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred1, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", fontsize=18, rotation=0)
plt.legend(loc="upper center", fontsize=18)
plt.title("No restrictions", fontsize=14)
plt.subplot(122)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred2, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.title("min_samples_leaf={}".format(tree_reg2.min_samples_leaf), fontsize=14)
plt.show()
As stated above and seen in many of the examples discussed here about a single decision tree, we often end up overfitting our training data. This normally means that we have a high variance. Can we reduce the variance of a statistical learning method?
This leads us to a set of different methods that can combine different machine learning algorithms or just use one of them to construct forests and jungles of trees, homogeneous ones or heterogenous ones. These methods are recognized by different names which we will try to explain here. These are
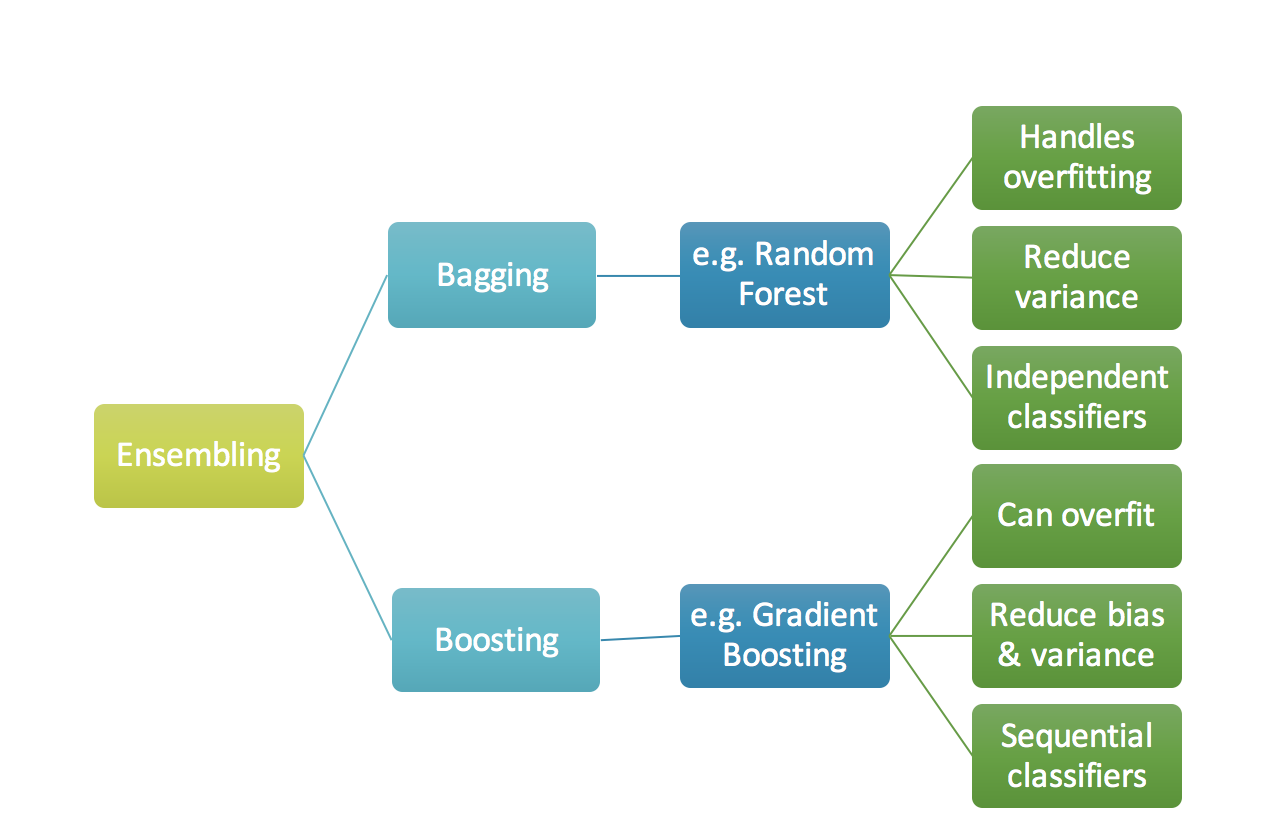
The plain decision trees suffer from high variance. This means that if we split the training data into two parts at random, and fit a decision tree to both halves, the results that we get could be quite different. In contrast, a procedure with low variance will yield similar results if applied repeatedly to distinct data sets; linear regression tends to have low variance, if the ratio of \( n \) to \( p \) is moderately large.
Bootstrap aggregation, or just bagging, is a general-purpose procedure for reducing the variance of a statistical learning method.
Bagging typically results in improved accuracy over prediction using a single tree. Unfortunately, however, it can be difficult to interpret the resulting model. Recall that one of the advantages of decision trees is the attractive and easily interpreted diagram that results.
However, when we bag a large number of trees, it is no longer possible to represent the resulting statistical learning procedure using a single tree, and it is no longer clear which variables are most important to the procedure. Thus, bagging improves prediction accuracy at the expense of interpretability. Although the collection of bagged trees is much more difficult to interpret than a single tree, one can obtain an overall summary of the importance of each predictor using the MSE (for bagging regression trees) or the Gini index (for bagging classification trees). In the case of bagging regression trees, we can record the total amount that the MSE is decreased due to splits over a given predictor, averaged over all \( B \) possible trees. A large value indicates an important predictor. Similarly, in the context of bagging classification trees, we can add up the total amount that the Gini index is decreased by splits over a given predictor, averaged over all \( B \) trees.
heads_proba = 0.51
coin_tosses = (np.random.rand(10000, 10) < heads_proba).astype(np.int32)
cumulative_heads_ratio = np.cumsum(coin_tosses, axis=0) / np.arange(1, 10001).reshape(-1, 1)
plt.figure(figsize=(8,3.5))
plt.plot(cumulative_heads_ratio)
plt.plot([0, 10000], [0.51, 0.51], "k--", linewidth=2, label="51%")
plt.plot([0, 10000], [0.5, 0.5], "k-", label="50%")
plt.xlabel("Number of coin tosses")
plt.ylabel("Heads ratio")
plt.legend(loc="lower right")
plt.axis([0, 10000, 0.42, 0.58])
save_fig("votingsimple")
plt.show()
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(solver="liblinear", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42)
svm_clf = SVC(gamma="auto", random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
voting_clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
log_clf = LogisticRegression(solver="liblinear", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42)
svm_clf = SVC(gamma="auto", probability=True, random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft')
voting_clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(random_state=42)
rnd_clf = RandomForestClassifier(random_state=42)
svm_clf = SVC(random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
voting_clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
log_clf = LogisticRegression(random_state=42)
rnd_clf = RandomForestClassifier(random_state=42)
svm_clf = SVC(probability=True, random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft')
voting_clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_pred))
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
y_pred_tree = tree_clf.predict(X_test)
print(accuracy_score(y_test, y_pred_tree))
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[-1.5, 2.5, -1, 1.5], alpha=0.5, contour=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
if contour:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", alpha=alpha)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", alpha=alpha)
plt.axis(axes)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
plt.figure(figsize=(11,4))
plt.subplot(121)
plot_decision_boundary(tree_clf, X, y)
plt.title("Decision Tree", fontsize=14)
plt.subplot(122)
plot_decision_boundary(bag_clf, X, y)
plt.title("Decision Trees with Bagging", fontsize=14)
save_fig("baggingtree")
plt.show()
Let us bring up our good old boostrap example from the linear regression lectures. We change the linerar regression algorithm with a decision tree wth different depths and perform a bootstrap aggregate (in this case we perform as many bootstraps as data points \( n \)).
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.utils import resample
from sklearn.tree import DecisionTreeRegressor
n = 100
n_boostraps = 100
maxdepth = 8
# Make data set.
x = np.linspace(-3, 3, n).reshape(-1, 1)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.normal(0, 0.1, x.shape)
error = np.zeros(maxdepth)
bias = np.zeros(maxdepth)
variance = np.zeros(maxdepth)
polydegree = np.zeros(maxdepth)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# we produce a simple tree first as benchmark
simpletree = DecisionTreeRegressor(max_depth=3)
simpletree.fit(X_train_scaled, y_train)
simpleprediction = simpletree.predict(X_test_scaled)
for degree in range(1,maxdepth):
model = DecisionTreeRegressor(max_depth=degree)
y_pred = np.empty((y_test.shape[0], n_boostraps))
for i in range(n_boostraps):
x_, y_ = resample(X_train_scaled, y_train)
model.fit(x_, y_)
y_pred[:, i] = model.predict(X_test_scaled)#.ravel()
polydegree[degree] = degree
error[degree] = np.mean( np.mean((y_test - y_pred)**2, axis=1, keepdims=True) )
bias[degree] = np.mean( (y_test - np.mean(y_pred, axis=1, keepdims=True))**2 )
variance[degree] = np.mean( np.var(y_pred, axis=1, keepdims=True) )
print('Polynomial degree:', degree)
print('Error:', error[degree])
print('Bias^2:', bias[degree])
print('Var:', variance[degree])
print('{} >= {} + {} = {}'.format(error[degree], bias[degree], variance[degree], bias[degree]+variance[degree]))
mse_simpletree = np.mean( np.mean((y_test - simpleprediction)**2)
plt.xlim(1,maxdepth)
plt.plot(polydegree, error, label='MSE simple tree')
plt.plot(polydegree, mse_simpletree, label='MSE for Bootstrap')
plt.plot(polydegree, bias, label='bias')
plt.plot(polydegree, variance, label='Variance')
plt.legend()
save_fig("baggingboot")
plt.show()
Random forests provide an improvement over bagged trees by way of a small tweak that decorrelates the trees.
As in bagging, we build a number of decision trees on bootstrapped training samples. But when building these decision trees, each time a split in a tree is considered, a random sample of \( m \) predictors is chosen as split candidates from the full set of \( p \) predictors. The split is allowed to use only one of those \( m \) predictors.
A fresh sample of \( m \) predictors is taken at each split, and typically we choose $$ m\approx \sqrt{p}. $$
In building a random forest, at each split in the tree, the algorithm is not even allowed to consider a majority of the available predictors.
The reason for this is rather clever. Suppose that there is one very strong predictor in the data set, along with a number of other moderately strong predictors. Then in the collection of bagged variable importance random forest trees, most or all of the trees will use this strong predictor in the top split. Consequently, all of the bagged trees will look quite similar to each other. Hence the predictions from the bagged trees will be highly correlated. Unfortunately, averaging many highly correlated quantities does not lead to as large of a reduction in variance as averaging many uncorrelated quantities. In particular, this means that bagging will not lead to a substantial reduction in variance over a single tree in this setting.
We will grow of forest of say \( B \) trees.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
# Load the data
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,cancer.target,random_state=0)
print(X_train.shape)
print(X_test.shape)
# Logistic Regression
logreg = LogisticRegression(solver='lbfgs')
logreg.fit(X_train, y_train)
print("Test set accuracy with Logistic Regression: {:.2f}".format(logreg.score(X_test,y_test)))
# Support vector machine
svm = SVC(gamma='auto', C=100)
svm.fit(X_train, y_train)
print("Test set accuracy with SVM: {:.2f}".format(svm.score(X_test,y_test)))
# Decision Trees
deep_tree_clf = DecisionTreeClassifier(max_depth=None)
deep_tree_clf.fit(X_train, y_train)
print("Test set accuracy with Decision Trees: {:.2f}".format(deep_tree_clf.score(X_test,y_test)))
#now scale the data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Logistic Regression
logreg.fit(X_train_scaled, y_train)
print("Test set accuracy Logistic Regression with scaled data: {:.2f}".format(logreg.score(X_test_scaled,y_test)))
# Support Vector Machine
svm.fit(X_train_scaled, y_train)
print("Test set accuracy SVM with scaled data: {:.2f}".format(logreg.score(X_test_scaled,y_test)))
# Decision Trees
deep_tree_clf.fit(X_train_scaled, y_train)
print("Test set accuracy with Decision Trees and scaled data: {:.2f}".format(deep_tree_clf.score(X_test_scaled,y_test)))
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_validate
# Data set not specificied
#Instantiate the model with 500 trees and entropy as splitting criteria
Random_Forest_model = RandomForestClassifier(n_estimators=500,criterion="entropy")
Random_Forest_model.fit(X_train_scaled, y_train)
#Cross validation
accuracy = cross_validate(Random_Forest_model,X_test_scaled,y_test,cv=10)['test_score']
print(accuracy)
print("Test set accuracy with Random Forests and scaled data: {:.2f}".format(Random_Forest_model.score(X_test_scaled,y_test)))
import scikitplot as skplt
y_pred = Random_Forest_model.predict(X_test_scaled)
skplt.metrics.plot_confusion_matrix(y_test, y_pred, normalize=True)
plt.show()
y_probas = Random_Forest_model.predict_proba(X_test_scaled)
skplt.metrics.plot_roc(y_test, y_probas)
plt.show()
skplt.metrics.plot_cumulative_gain(y_test, y_probas)
plt.show()
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_leaf_nodes=16, random_state=42),
n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
np.sum(y_pred == y_pred_rf) / len(y_pred)
The basic idea is to combine weak classifiers in order to create a good classifier. With a weak classifier we often intend a classifier which produces results which are only slightly better than we would get by random guesses.
This is done by applying in an iterative way a weak (or a standard classifier like decision trees) to modify the data. In each iteration we emphasize those observations which are misclassified by weighting them with a factor.
Boosting is a way of fitting an additive expansion in a set of elementary basis functions like for example some simple polynomials. Assume for example that we have a function $$ f_M(x) = \sum_{i=1}^M \beta_m b(x;\gamma_m), $$
where \( \beta_m \) are the expansion parameters to be determined in a minimization process and \( b(x;\gamma_m) \) are some simple functions of the multivariable parameter \( x \) which is characterized by the parameters \( \gamma_m \).
As an example, consider the Sigmoid function we used in logistic regression. In that case, we can translate the function \( b(x;\gamma_m) \) into the Sigmoid function $$ \sigma(t) = \frac{1}{1+\exp{(-t)}}, $$
where \( t=\gamma_0+\gamma_1 x \) and the parameters \( \gamma_0 \) and \( \gamma_1 \) were determined by the Logistic Regression fitting algorithm.
As another example, consider the cost function we defined for linear regression $$ C(\boldsymbol{y},\boldsymbol{f}) = \frac{1}{n} \sum_{i=0}^{n-1}(y_i-f(x_i))^2. $$
In this case the function \( f(x) \) was replaced by the design matrix \( \boldsymbol{X} \) and the unknown linear regression parameters \( \boldsymbol{\beta} \), that is \( \boldsymbol{f}=\boldsymbol{X}\boldsymbol{\beta} \). In linear regression we can simply invert a matrix and obtain the parameters \( \beta \) by $$ \boldsymbol{\beta}=\left(\boldsymbol{X}^T\boldsymbol{X}\right)^{-1}\boldsymbol{X}^T\boldsymbol{y}. $$
In iterative fitting or additive modeling, we minimize the cost function with respect to the parameters \( \beta_m \) and \( \gamma_m \).
The way we proceed is as follows (here we specialize to the squared-error cost function)
To better understand what happens, let us develop the steps for the iterative fitting using the above squared error function.
For simplicity we assume also that our functions \( b(x;\gamma)=1+\gamma x \).
This means that for every iteration \( m \), we need to optimize $$ (\beta_m,\gamma_m) = \mathrm{argmin}_{\beta,\lambda}\hspace{0.1cm} \sum_{i=0}^{n-1}(y_i-f_{m-1}(x_i)-\beta b(x;\gamma))^2=\sum_{i=0}^{n-1}(y_i-f_{m-1}(x_i)-\beta(1+\gamma x_i))^2. $$
We start our iteration by simply setting \( f_0(x)=0 \). Taking the derivatives with respect to \( \beta \) and \( \gamma \) we obtain $$ \frac{\partial {\cal C}}{\partial \beta} = -2\sum_{i}(1+\gamma x_i)(y_i-\beta(1+\gamma x_i))=0, $$ and $$ \frac{\partial {\cal C}}{\partial \gamma} =-2\sum_{i}\beta x_i(y_i-\beta(1+\gamma x_i))=0. $$ We can then rewrite these equations as (defining \( \boldsymbol{w}=\boldsymbol{e}+\gamma \boldsymbol{x}) \) with \( \boldsymbol{e} \) being the unit vector) $$ \gamma \boldsymbol{w}^T(\boldsymbol{y}-\beta\gamma \boldsymbol{w})=0, $$ which gives us \( \beta = \boldsymbol{w}^T\boldsymbol{y}/(\boldsymbol{w}^T\boldsymbol{w}) \). Similarly we have $$ \beta\gamma \boldsymbol{x}^T(\boldsymbol{y}-\beta(1+\gamma \boldsymbol{x}))=0, $$
which leads to \( \gamma =(\boldsymbol{x}^T\boldsymbol{y}-\beta\boldsymbol{x}^T\boldsymbol{e})/(\beta\boldsymbol{x}^T\boldsymbol{x}) \). Inserting for \( \beta \) gives us an equation for \( \gamma \). This is a non-linear equation in the unknown \( \gamma \) and has to be solved numerically.
The solution to these two equations gives us in turn \( \beta_1 \) and \( \gamma_1 \) leading to the new expression for \( f_1(x) \) as \( f_1(x) = \beta_1(1+\gamma_1x) \). Doing this \( M \) times results in our final estimate for the function \( f \).
Let us consider a binary classification problem with two outcomes \( y_i \in \{-1,1\} \) and \( i=0,1,2,\dots,n-1 \) as our set of observations. We define a classification function \( G(x) \) which produces a prediction taking one or the other of the two values \( \{-1,1\} \).
The error rate of the training sample is then $$ \mathrm{\overline{err}}=\frac{1}{n} \sum_{i=0}^{n-1} I(y_i\ne G(x_i)). $$
The iterative procedure starts with defining a weak classifier whose error rate is barely better than random guessing. The iterative procedure in boosting is to sequentially apply a weak classification algorithm to repeatedly modified versions of the data producing a sequence of weak classifiers \( G_m(x) \).
Here we will express our function \( f(x) \) in terms of \( G(x) \). That is $$ f_M(x) = \sum_{i=1}^M \beta_m b(x;\gamma_m), $$ will be a function of $$ G_M(x) = \mathrm{sign} \sum_{i=1}^M \alpha_m G_m(x). $$
In our iterative procedure we define thus $$ f_m(x) = f_{m-1}(x)+\beta_mG_m(x). $$
The simplest possible cost function which leads (also simple from a computational point of view) to the AdaBoost algorithm is the exponential cost/loss function defined as $$ C(\boldsymbol{y},\boldsymbol{f}) = \sum_{i=0}^{n-1}\exp{(-y_i(f_{m-1}(x_i)+\beta G(x_i))}. $$
We optimize \( \beta \) and \( G \) for each value of \( m=1:M \) as we did in the regression case. This is normally done in two steps. Let us however first rewrite the cost function as $$ C(\boldsymbol{y},\boldsymbol{f}) = \sum_{i=0}^{n-1}w_i^{m}\exp{(-y_i\beta G(x_i))}, $$ where we have defined \( w_i^m= \exp{(-y_if_{m-1}(x_i))} \).
First, for any \( \beta > 0 \), we optimize \( G \) by setting $$ G_m(x) = \mathrm{sign} \sum_{i=0}^{n-1} w_i^m I(y_i \ne G_(x_i)), $$ which is the classifier that minimizes the weighted error rate in predicting \( y \).
We can do this by rewriting $$ \exp{-(\beta)}\sum_{y_i=G(x_i)}w_i^m+\exp{(\beta)}\sum_{y_i\ne G(x_i)}w_i^m, $$ which can be rewritten as $$ (\exp{(\beta)}-\exp{-(\beta)})\sum_{i=0}^{n-1}w_i^mI(y_i\ne G(x_i))+\exp{(-\beta)}\sum_{i=0}^{n-1}w_i^m=0, $$ which leads to $$ \beta_m = \frac{1}{2}\log{\frac{1-\mathrm{\overline{err}}}{\mathrm{\overline{err}}}}, $$ where we have redefined the error as $$ \mathrm{\overline{err}}_m=\frac{1}{n}\frac{\sum_{i=0}^{n-1}w_i^mI(y_i\ne G(x_i)}{\sum_{i=0}^{n-1}w_i^m}, $$ which leads to an update of $$ f_m(x) = f_{m-1}(x) +\beta_m G_m(x). $$ This leads to the new weights $$ w_i^{m+1} = w_i^m \exp{(-y_i\beta_m G_m(x_i))} $$
The algorithm here is rather straightforward. Assume that our weak classifier is a decision tree and we consider a binary set of outputs with \( y_i \in \{-1,1\} \) and \( i=0,1,2,\dots,n-1 \) as our set of observations. Our design matrix is given in terms of the feature/predictor vectors \( \boldsymbol{X}=[\boldsymbol{x}_0\boldsymbol{x}_1\dots\boldsymbol{x}_{p-1}] \). Finally, we define also a classifier determined by our data via a function \( G(x) \). This function tells us how well we are able to classify our outputs/targets \( \boldsymbol{y} \).
We have already defined the misclassification error \( \mathrm{err} \) as $$ \mathrm{err}=\frac{1}{n}\sum_{i=0}^{n-1}I(y_i\ne G(x_i)), $$ where the function \( I() \) is one if we misclassify and zero if we classify correctly.
With the above definitions we are now ready to set up the algorithm for AdaBoost. The basic idea is to set up weights which will be used to scale the correctly classified and the misclassified cases.
Using Scikit-Learn it is easy to apply the adaptive boosting algorithm, as done here.
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train_scaled, y_train)
y_pred = ada_clf.predict(X_test_scaled)
skplt.metrics.plot_confusion_matrix(y_test, y_pred, normalize=True)
plt.show()
y_probas = ada_clf.predict_proba(X_test_scaled)
skplt.metrics.plot_roc(y_test, y_probas)
plt.show()
skplt.metrics.plot_cumulative_gain(y_test, y_probas)
plt.show()
Here we present Drucker's AdaBoost tailored for regression.
In bagging, each training example is equally likely to be picked. In boosting, the probability of a particular example being in the training set of a particular machine depends on the performance of the prior machines on that example. The following is a modification of Adaboost by Drucker.
Start by selecting a set of training data \( n \) and assign to each entry a weight \( w_i=1 \) for \( i=1,2,\dots,n \). As we have done earlier, we could pick say \( 80\% \) of the data set for training. The algorithm runs as follows:
Gradient boosting is again a similar technique to Adaptive boosting, it combines so-called weak classifiers or regressors into a strong method via a series of iterations.
In order to understand the method, let us illustrate its basics by bringing back the essential steps in linear regression, where our cost function was the least squares function.
We start again with our cost function \( {\cal C}(\boldsymbol{y}m\boldsymbol{f})=\sum_{i=0}^{n-1}{\cal L}(y_i, f(x_i)) \) where we want to minimize This means that for every iteration, we need to optimize $$ (\hat{\boldsymbol{f}}) = \mathrm{argmin}_{\boldsymbol{f}}\hspace{0.1cm} \sum_{i=0}^{n-1}(y_i-f(x_i))^2. $$
We define a real function \( h_m(x) \) that defines our final function \( f_M(x) \) as $$ f_M(x) = \sum_{m=0}^M h_m(x). $$
In the steepest decent approach we approximate \( h_m(x) = -\rho_m g_m(x) \), where \( \rho_m \) is a scalar and \( g_m(x) \) the gradient defined as $$ g_m(x_i) = \left[ \frac{\partial {\cal L}(y_i, f(x_i))}{\partial f(x_i)}\right]_{f(x_i)=f_{m-1}(x_i)}. $$
With the new gradient we can update \( f_m(x) = f_{m-1}(x) -\rho_m g_m(x) \). Using the above squared-error function we see that the gradient is \( g_m(x_i) = -2(y_i-f(x_i)) \).
Choosing \( f_0(x)=0 \) we obtain \( g_m(x) = -2y_i \) and inserting this into the minimization problem for the cost function we have $$ (\rho_1) = \mathrm{argmin}_{\rho}\hspace{0.1cm} \sum_{i=0}^{n-1}(y_i+2\rho y_i)^2. $$
Optimizing with respect to \( \rho \) we obtain (taking the derivative) that \( \rho_1 = -1/2 \). We have then that $$ f_1(x) = f_{0}(x) -\rho_1 g_1(x)=-y_i. $$ We can then proceed and compute $$ g_2(x_i) = \left[ \frac{\partial {\cal L}(y_i, f(x_i))}{\partial f(x_i)}\right]_{f(x_i)=f_{1}(x_i)=y_i}=-4y_i, $$ and find a new value for \( \rho_2=-1/2 \) and continue till we have reached \( m=M \). We can modify the steepest descent method, or steepest boosting, by introducing what is called gradient boosting.
Suppose we have a cost function \( C(f)=\sum_{i=0}^{n-1}L(y_i, f(x_i)) \) where \( y_i \) is our target and \( f(x_i) \) the function which is meant to model \( y_i \). The above cost function could be our standard squared-error function $$ C(\boldsymbol{y},\boldsymbol{f})=\sum_{i=0}^{n-1}(y_i-f(x_i))^2. $$
The way we proceed in an iterative fashion is to
We discuss here the difference between the steepest descent approach and gradient boosting by repeating our simple regression example above.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.preprocessing import StandardScaler
import scikitplot as skplt
from sklearn.metrics import mean_squared_error
n = 100
maxdegree = 6
# Make data set.
x = np.linspace(-3, 3, n).reshape(-1, 1)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.normal(0, 0.1, x.shape)
error = np.zeros(maxdegree)
bias = np.zeros(maxdegree)
variance = np.zeros(maxdegree)
polydegree = np.zeros(maxdegree)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
for degree in range(1,maxdegree):
model = GradientBoostingRegressor(max_depth=degree, n_estimators=100, learning_rate=1.0)
model.fit(X_train_scaled,y_train)
y_pred = model.predict(X_test_scaled)
polydegree[degree] = degree
error[degree] = np.mean( np.mean((y_test - y_pred)**2) )
bias[degree] = np.mean( (y_test - np.mean(y_pred))**2 )
variance[degree] = np.mean( np.var(y_pred) )
print('Max depth:', degree)
print('Error:', error[degree])
print('Bias^2:', bias[degree])
print('Var:', variance[degree])
print('{} >= {} + {} = {}'.format(error[degree], bias[degree], variance[degree], bias[degree]+variance[degree]))
plt.xlim(1,maxdegree-1)
plt.plot(polydegree, error, label='Error')
plt.plot(polydegree, bias, label='bias')
plt.plot(polydegree, variance, label='Variance')
plt.legend()
save_fig("gdregression")
plt.show()
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import scikitplot as skplt
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_validate
# Load the data
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,cancer.target,random_state=0)
print(X_train.shape)
print(X_test.shape)
#now scale the data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
gd_clf = GradientBoostingClassifier(max_depth=3, n_estimators=100, learning_rate=1.0)
gd_clf.fit(X_train_scaled, y_train)
#Cross validation
accuracy = cross_validate(gd_clf,X_test_scaled,y_test,cv=10)['test_score']
print(accuracy)
print("Test set accuracy with Random Forests and scaled data: {:.2f}".format(gd_clf.score(X_test_scaled,y_test)))
import scikitplot as skplt
y_pred = gd_clf.predict(X_test_scaled)
skplt.metrics.plot_confusion_matrix(y_test, y_pred, normalize=True)
save_fig("gdclassiffierconfusion")
plt.show()
y_probas = gd_clf.predict_proba(X_test_scaled)
skplt.metrics.plot_roc(y_test, y_probas)
save_fig("gdclassiffierroc")
plt.show()
skplt.metrics.plot_cumulative_gain(y_test, y_probas)
save_fig("gdclassiffiercgain")
plt.show()
XGBoost or Extreme Gradient Boosting, is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting that solve many data science problems in a fast and accurate way. See the article by Chen and Guestrin.
The authors design and build a highly scalable end-to-end tree boosting system. It has a theoretically justified weighted quantile sketch for efficient proposal calculation. It introduces a novel sparsity-aware algorithm for parallel tree learning and an effective cache-aware block structure for out-of-core tree learning.
It is now the algorithm which wins essentially all ML competitions!!!
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.preprocessing import StandardScaler
import scikitplot as skplt
from sklearn.metrics import mean_squared_error
n = 100
maxdegree = 6
# Make data set.
x = np.linspace(-3, 3, n).reshape(-1, 1)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.normal(0, 0.1, x.shape)
error = np.zeros(maxdegree)
bias = np.zeros(maxdegree)
variance = np.zeros(maxdegree)
polydegree = np.zeros(maxdegree)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
for degree in range(maxdegree):
model = xgb.XGBRegressor(objective ='reg:squarederror', colsaobjective ='reg:squarederror', colsample_bytree = 0.3, learning_rate = 0.1,max_depth = degree, alpha = 10, n_estimators = 200)
model.fit(X_train_scaled,y_train)
y_pred = model.predict(X_test_scaled)
polydegree[degree] = degree
error[degree] = np.mean( np.mean((y_test - y_pred)**2) )
bias[degree] = np.mean( (y_test - np.mean(y_pred))**2 )
variance[degree] = np.mean( np.var(y_pred) )
print('Max depth:', degree)
print('Error:', error[degree])
print('Bias^2:', bias[degree])
print('Var:', variance[degree])
print('{} >= {} + {} = {}'.format(error[degree], bias[degree], variance[degree], bias[degree]+variance[degree]))
plt.xlim(1,maxdegree-1)
plt.plot(polydegree, error, label='Error')
plt.plot(polydegree, bias, label='bias')
plt.plot(polydegree, variance, label='Variance')
plt.legend()
plt.show()
As you will see from the confusion matrix below, XGBoots does an excellent job on the Wisconsin cancer data and outperforms essentially all agorithms we have discussed till now.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_validate
import scikitplot as skplt
import xgboost as xgb
# Load the data
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,cancer.target,random_state=0)
print(X_train.shape)
print(X_test.shape)
#now scale the data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
xg_clf = xgb.XGBClassifier()
xg_clf.fit(X_train_scaled,y_train)
y_test = xg_clf.predict(X_test_scaled)
print("Test set accuracy with Random Forests and scaled data: {:.2f}".format(xg_clf.score(X_test_scaled,y_test)))
import scikitplot as skplt
y_pred = xg_clf.predict(X_test_scaled)
skplt.metrics.plot_confusion_matrix(y_test, y_pred, normalize=True)
save_fig("xdclassiffierconfusion")
plt.show()
y_probas = xg_clf.predict_proba(X_test_scaled)
skplt.metrics.plot_roc(y_test, y_probas)
save_fig("xdclassiffierroc")
plt.show()
skplt.metrics.plot_cumulative_gain(y_test, y_probas)
save_fig("gdclassiffiercgain")
plt.show()
xgb.plot_tree(xg_clf,num_trees=0)
plt.rcParams['figure.figsize'] = [50, 10]
save_fig("xgtree")
plt.show()
xgb.plot_importance(xg_clf)
plt.rcParams['figure.figsize'] = [5, 5]
save_fig("xgparams")
plt.show()