Neural Networks
Contents
13. Neural Networks¶
13.1. Introduction¶
Artificial neural networks are computational systems that can learn to perform tasks by considering examples, generally without being programmed with any task-specific rules. It is supposed to mimic a biological system, wherein neurons interact by sending signals in the form of mathematical functions between layers. All layers can contain an arbitrary number of neurons, and each connection is represented by a weight variable.
The field of artificial neural networks has a long history of development, and is closely connected with the advancement of computer science and computers in general. A model of artificial neurons was first developed by McCulloch and Pitts in 1943 to study signal processing in the brain and has later been refined by others. The general idea is to mimic neural networks in the human brain, which is composed of billions of neurons that communicate with each other by sending electrical signals. Each neuron accumulates its incoming signals, which must exceed an activation threshold to yield an output. If the threshold is not overcome, the neuron remains inactive, i.e. has zero output.
This behaviour has inspired a simple mathematical model for an artificial neuron.
Here, the output \(y\) of the neuron is the value of its activation function, which have as input a weighted sum of signals \(x_i, \dots ,x_n\) received by \(n\) other neurons.
Conceptually, it is helpful to divide neural networks into four categories:
general purpose neural networks for supervised learning,
neural networks designed specifically for image processing, the most prominent example of this class being Convolutional Neural Networks (CNNs),
neural networks for sequential data such as Recurrent Neural Networks (RNNs), and
neural networks for unsupervised learning such as Deep Boltzmann Machines.
In natural science, DNNs and CNNs have already found numerous applications. In statistical physics, they have been applied to detect phase transitions in 2D Ising and Potts models, lattice gauge theories, and different phases of polymers, or solving the Navier-Stokes equation in weather forecasting. Deep learning has also found interesting applications in quantum physics. Various quantum phase transitions can be detected and studied using DNNs and CNNs, topological phases, and even non-equilibrium many-body localization. Representing quantum states as DNNs quantum state tomography are among some of the impressive achievements to reveal the potential of DNNs to facilitate the study of quantum systems.
In quantum information theory, it has been shown that one can perform gate decompositions with the help of neural.
The applications are not limited to the natural sciences. There is a plethora of applications in essentially all disciplines, from the humanities to life science and medicine.
An artificial neural network (ANN), is a computational model that consists of layers of connected neurons, or nodes or units. We will refer to these interchangeably as units or nodes, and sometimes as neurons.
It is supposed to mimic a biological nervous system by letting each neuron interact with other neurons by sending signals in the form of mathematical functions between layers. A wide variety of different ANNs have been developed, but most of them consist of an input layer, an output layer and eventual layers in-between, called hidden layers. All layers can contain an arbitrary number of nodes, and each connection between two nodes is associated with a weight variable.
Neural networks (also called neural nets) are neural-inspired nonlinear models for supervised learning. As we will see, neural nets can be viewed as natural, more powerful extensions of supervised learning methods such as linear and logistic regression and soft-max methods we discussed earlier.
13.1.1. Feed-forward neural networks¶
The feed-forward neural network (FFNN) was the first and simplest type of ANNs that were devised. In this network, the information moves in only one direction: forward through the layers.
Nodes are represented by circles, while the arrows display the connections between the nodes, including the direction of information flow. Additionally, each arrow corresponds to a weight variable (figure to come). We observe that each node in a layer is connected to all nodes in the subsequent layer, making this a so-called fully-connected FFNN.
13.1.2. Convolutional Neural Network¶
A different variant of FFNNs are convolutional neural networks (CNNs), which have a connectivity pattern inspired by the animal visual cortex. Individual neurons in the visual cortex only respond to stimuli from small sub-regions of the visual field, called a receptive field. This makes the neurons well-suited to exploit the strong spatially local correlation present in natural images. The response of each neuron can be approximated mathematically as a convolution operation. (figure to come)
Convolutional neural networks emulate the behaviour of neurons in the visual cortex by enforcing a local connectivity pattern between nodes of adjacent layers: Each node in a convolutional layer is connected only to a subset of the nodes in the previous layer, in contrast to the fully-connected FFNN. Often, CNNs consist of several convolutional layers that learn local features of the input, with a fully-connected layer at the end, which gathers all the local data and produces the outputs. They have wide applications in image and video recognition.
13.1.3. Recurrent neural networks¶
So far we have only mentioned ANNs where information flows in one direction: forward. Recurrent neural networks on the other hand, have connections between nodes that form directed cycles. This creates a form of internal memory which are able to capture information on what has been calculated before; the output is dependent on the previous computations. Recurrent NNs make use of sequential information by performing the same task for every element in a sequence, where each element depends on previous elements. An example of such information is sentences, making recurrent NNs especially well-suited for handwriting and speech recognition.
13.1.4. Other types of networks¶
There are many other kinds of ANNs that have been developed. One type that is specifically designed for interpolation in multidimensional space is the radial basis function (RBF) network. RBFs are typically made up of three layers: an input layer, a hidden layer with non-linear radial symmetric activation functions and a linear output layer (‘’linear’’ here means that each node in the output layer has a linear activation function). The layers are normally fully-connected and there are no cycles, thus RBFs can be viewed as a type of fully-connected FFNN. They are however usually treated as a separate type of NN due the unusual activation functions.
13.2. Multilayer perceptrons¶
One uses often so-called fully-connected feed-forward neural networks with three or more layers (an input layer, one or more hidden layers and an output layer) consisting of neurons that have non-linear activation functions.
Such networks are often called multilayer perceptrons (MLPs).
According to the Universal approximation theorem, a feed-forward neural network with just a single hidden layer containing a finite number of neurons can approximate a continuous multidimensional function to arbitrary accuracy, assuming the activation function for the hidden layer is a non-constant, bounded and monotonically-increasing continuous function.
Note that the requirements on the activation function only applies to the hidden layer, the output nodes are always assumed to be linear, so as to not restrict the range of output values.
The output \(y\) is produced via the activation function \(f\)
This function receives \(x_i\) as inputs. Here the activation \(z=(\sum_{i=1}^n w_ix_i+b_i)\). In an FFNN of such neurons, the inputs \(x_i\) are the outputs of the neurons in the preceding layer. Furthermore, an MLP is fully-connected, which means that each neuron receives a weighted sum of the outputs of all neurons in the previous layer.
First, for each node \(i\) in the first hidden layer, we calculate a weighted sum \(z_i^1\) of the input coordinates \(x_j\),
Here \(b_i\) is the so-called bias which is normally needed in case of zero activation weights or inputs. How to fix the biases and the weights will be discussed below. The value of \(z_i^1\) is the argument to the activation function \(f_i\) of each node \(i\), The variable \(M\) stands for all possible inputs to a given node \(i\) in the first layer. We define the output \(y_i^1\) of all neurons in layer 1 as
where we assume that all nodes in the same layer have identical activation functions, hence the notation \(f\). In general, we could assume in the more general case that different layers have different activation functions. In this case we would identify these functions with a superscript \(l\) for the \(l\)-th layer,
where \(N_l\) is the number of nodes in layer \(l\). When the output of all the nodes in the first hidden layer are computed, the values of the subsequent layer can be calculated and so forth until the output is obtained.
The output of neuron \(i\) in layer 2 is thus,
where we have substituted \(y_k^1\) with the inputs \(x_k\). Finally, the ANN output reads
We can generalize this expression to an MLP with \(l\) hidden layers. The complete functional form is,
which illustrates a basic property of MLPs: The only independent variables are the input values \(x_n\).
This confirms that an MLP, despite its quite convoluted mathematical form, is nothing more than an analytic function, specifically a mapping of real-valued vectors \(\hat{x} \in \mathbb{R}^n \rightarrow \hat{y} \in \mathbb{R}^m\).
Furthermore, the flexibility and universality of an MLP can be illustrated by realizing that the expression is essentially a nested sum of scaled activation functions of the form
where the parameters \(c_i\) are weights and biases. By adjusting these parameters, the activation functions can be shifted up and down or left and right, change slope or be rescaled which is the key to the flexibility of a neural network.
We can introduce a more convenient notation for the activations in an A NN.
Additionally, we can represent the biases and activations as layer-wise column vectors \(\hat{b}_l\) and \(\hat{y}_l\), so that the \(i\)-th element of each vector is the bias \(b_i^l\) and activation \(y_i^l\) of node \(i\) in layer \(l\) respectively.
We have that \(\mathrm{W}_l\) is an \(N_{l-1} \times N_l\) matrix, while \(\hat{b}_l\) and \(\hat{y}_l\) are \(N_l \times 1\) column vectors. With this notation, the sum becomes a matrix-vector multiplication, and we can write the equation for the activations of hidden layer 2 (assuming three nodes for simplicity) as
The activation of node \(i\) in layer 2 is
This is not just a convenient and compact notation, but also a useful and intuitive way to think about MLPs: The output is calculated by a series of matrix-vector multiplications and vector additions that are used as input to the activation functions. For each operation \(\mathrm{W}_l \hat{y}_{l-1}\) we move forward one layer.
13.2.1. Activation functions¶
A property that characterizes a neural network, other than its connectivity, is the choice of activation function(s). As described in, the following restrictions are imposed on an activation function for a FFNN to fulfill the universal approximation theorem
Non-constant
Bounded
Monotonically-increasing
Continuous
The second requirement excludes all linear functions. Furthermore, in a MLP with only linear activation functions, each layer simply performs a linear transformation of its inputs.
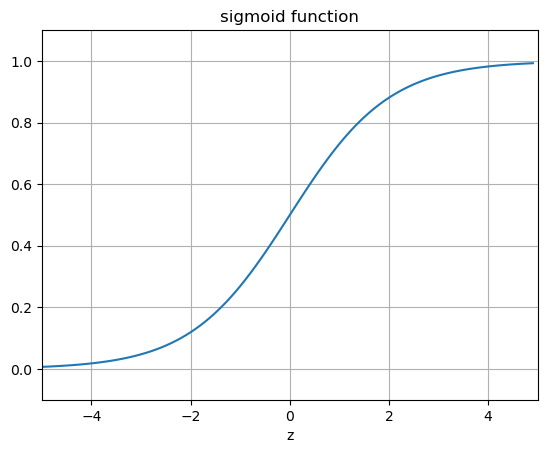
Regardless of the number of layers, the output of the NN will be nothing but a linear function of the inputs. Thus we need to introduce some kind of non-linearity to the NN to be able to fit non-linear functions Typical examples are the logistic Sigmoid
and the hyperbolic tangent function
The sigmoid function are more biologically plausible because the output of inactive neurons are zero. Such activation function are called one-sided. However, it has been shown that the hyperbolic tangent performs better than the sigmoid for training MLPs. has become the most popular for deep neural networks
%matplotlib inline
"""The sigmoid function (or the logistic curve) is a
function that takes any real number, z, and outputs a number (0,1).
It is useful in neural networks for assigning weights on a relative scale.
The value z is the weighted sum of parameters involved in the learning algorithm."""
import numpy
import matplotlib.pyplot as plt
import math as mt
z = numpy.arange(-5, 5, .1)
sigma_fn = numpy.vectorize(lambda z: 1/(1+numpy.exp(-z)))
sigma = sigma_fn(z)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(z, sigma)
ax.set_ylim([-0.1, 1.1])
ax.set_xlim([-5,5])
ax.grid(True)
ax.set_xlabel('z')
ax.set_title('sigmoid function')
plt.show()
"""Step Function"""
z = numpy.arange(-5, 5, .02)
step_fn = numpy.vectorize(lambda z: 1.0 if z >= 0.0 else 0.0)
step = step_fn(z)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(z, step)
ax.set_ylim([-0.5, 1.5])
ax.set_xlim([-5,5])
ax.grid(True)
ax.set_xlabel('z')
ax.set_title('step function')
plt.show()
"""Sine Function"""
z = numpy.arange(-2*mt.pi, 2*mt.pi, 0.1)
t = numpy.sin(z)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(z, t)
ax.set_ylim([-1.0, 1.0])
ax.set_xlim([-2*mt.pi,2*mt.pi])
ax.grid(True)
ax.set_xlabel('z')
ax.set_title('sine function')
plt.show()
"""Plots a graph of the squashing function used by a rectified linear
unit"""
z = numpy.arange(-2, 2, .1)
zero = numpy.zeros(len(z))
y = numpy.max([zero, z], axis=0)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(z, y)
ax.set_ylim([-2.0, 2.0])
ax.set_xlim([-2.0, 2.0])
ax.grid(True)
ax.set_xlabel('z')
ax.set_title('Rectified linear unit')
plt.show()
13.3. The multilayer perceptron (MLP)¶
The multilayer perceptron is a very popular, and easy to implement approach, to deep learning. It consists of
A neural network with one or more layers of nodes between the input and the output nodes.
The multilayer network structure, or architecture, or topology, consists of an input layer, one or more hidden layers, and one output layer.
The input nodes pass values to the first hidden layer, its nodes pass the information on to the second and so on till we reach the output layer.
As a convention it is normal to call a network with one layer of input units, one layer of hidden units and one layer of output units as a two-layer network. A network with two layers of hidden units is called a three-layer network etc etc.
For an MLP network there is no direct connection between the output nodes/neurons/units and the input nodes/neurons/units. Hereafter we will call the various entities of a layer for nodes. There are also no connections within a single layer.
The number of input nodes does not need to equal the number of output nodes. This applies also to the hidden layers. Each layer may have its own number of nodes and activation functions.
The hidden layers have their name from the fact that they are not linked to observables and as we will see below when we define the so-called activation \(\hat{z}\), we can think of this as a basis expansion of the original inputs \(\hat{x}\). The difference however between neural networks and say linear regression is that now these basis functions (which will correspond to the weights in the network) are learned from data. This results in an important difference between neural networks and deep learning approaches on one side and methods like logistic regression or linear regression and their modifications on the other side.
13.3.1. From one to many layers, the universal approximation theorem¶
A neural network with only one layer, what we called the simple perceptron, is best suited if we have a standard binary model with clear (linear) boundaries between the outcomes. As such it could equally well be replaced by standard linear regression or logistic regression. Networks with one or more hidden layers approximate systems with more complex boundaries.
As stated earlier, an important theorem in studies of neural networks, restated without proof here, is the universal approximation theorem.
It states that a feed-forward network with a single hidden layer containing a finite number of neurons can approximate continuous functions on compact subsets of real functions. The theorem thus states that simple neural networks can represent a wide variety of interesting functions when given appropriate parameters. It is the multilayer feedforward architecture itself which gives neural networks the potential of being universal approximators.
13.4. Deriving the back propagation code for a multilayer perceptron model¶
As we have seen now in a feed forward network, we can express the final output of our network in terms of basic matrix-vector multiplications. The unknowwn quantities are our weights \(w_{ij}\) and we need to find an algorithm for changing them so that our errors are as small as possible. This leads us to the famous back propagation algorithm.
The questions we want to ask are how do changes in the biases and the weights in our network change the cost function and how can we use the final output to modify the weights?
To derive these equations let us start with a plain regression problem and define our cost function as
where the \(t_i\)s are our \(n\) targets (the values we want to reproduce), while the outputs of the network after having propagated all inputs \(\hat{x}\) are given by \(y_i\). Below we will demonstrate how the basic equations arising from the back propagation algorithm can be modified in order to study classification problems with \(K\) classes.
With our definition of the targets \(\hat{t}\), the outputs of the network \(\hat{y}\) and the inputs \(\hat{x}\) we define now the activation \(z_j^l\) of node/neuron/unit \(j\) of the \(l\)-th layer as a function of the bias, the weights which add up from the previous layer \(l-1\) and the forward passes/outputs \(\hat{a}^{l-1}\) from the previous layer as
where \(b_k^l\) are the biases from layer \(l\). Here \(M_{l-1}\) represents the total number of nodes/neurons/units of layer \(l-1\). The figure here illustrates this equation. We can rewrite this in a more compact form as the matrix-vector products we discussed earlier,
With the activation values \(\hat{z}^l\) we can in turn define the output of layer \(l\) as \(\hat{a}^l = f(\hat{z}^l)\) where \(f\) is our activation function. In the examples here we will use the sigmoid function discussed in our logistic regression lectures. We will also use the same activation function \(f\) for all layers and their nodes. It means we have
From the definition of the activation \(z_j^l\) we have
and
With our definition of the activation function we have that (note that this function depends only on \(z_j^l\))
With these definitions we can now compute the derivative of the cost function in terms of the weights.
Let us specialize to the output layer \(l=L\). Our cost function is
The derivative of this function with respect to the weights is
The last partial derivative can easily be computed and reads (by applying the chain rule)
We have thus
Defining
and using the Hadamard product of two vectors we can write this as
This is an important expression. The second term on the right handside measures how fast the cost function is changing as a function of the \(j\)th output activation. If, for example, the cost function doesn’t depend much on a particular output node \(j\), then \(\delta_j^L\) will be small, which is what we would expect. The first term on the right, measures how fast the activation function \(f\) is changing at a given activation value \(z_j^L\).
Notice that everything in the above equations is easily computed. In particular, we compute \(z_j^L\) while computing the behaviour of the network, and it is only a small additional overhead to compute \(f'(z^L_j)\). The exact form of the derivative with respect to the output depends on the form of the cost function. However, provided the cost function is known there should be little trouble in calculating
With the definition of \(\delta_j^L\) we have a more compact definition of the derivative of the cost function in terms of the weights, namely
It is also easy to see that our previous equation can be written as
which can also be interpreted as the partial derivative of the cost function with respect to the biases \(b_j^L\), namely
That is, the error \(\delta_j^L\) is exactly equal to the rate of change of the cost function as a function of the bias.
We have now three equations that are essential for the computations of the derivatives of the cost function at the output layer. These equations are needed to start the algorithm and they are
The starting equations.
and
and
An interesting consequence of the above equations is that when the activation \(a_k^{L-1}\) is small, the gradient term, that is the derivative of the cost function with respect to the weights, will also tend to be small. We say then that the weight learns slowly, meaning that it changes slowly when we minimize the weights via say gradient descent. In this case we say the system learns slowly.
Another interesting feature is that is when the activation function, represented by the sigmoid function here, is rather flat when we move towards its end values \(0\) and \(1\) (see the above Python codes). In these cases, the derivatives of the activation function will also be close to zero, meaning again that the gradients will be small and the network learns slowly again.
We need a fourth equation and we are set. We are going to propagate backwards in order to the determine the weights and biases. In order to do so we need to represent the error in the layer before the final one \(L-1\) in terms of the errors in the final output layer.
We have that (replacing \(L\) with a general layer \(l\))
We want to express this in terms of the equations for layer \(l+1\). Using the chain rule and summing over all \(k\) entries we have
and recalling that
with \(M_l\) being the number of nodes in layer \(l\), we obtain
This is our final equation.
We are now ready to set up the algorithm for back propagation and learning the weights and biases.
13.5. Setting up the Back propagation algorithm¶
The four equations provide us with a way of computing the gradient of the cost function. Let us write this out in the form of an algorithm.
First, we set up the input data \(\hat{x}\) and the activations \(\hat{z}_1\) of the input layer and compute the activation function and the pertinent outputs \(\hat{a}^1\).
Secondly, we perform then the feed forward till we reach the output layer and compute all \(\hat{z}_l\) of the input layer and compute the activation function and the pertinent outputs \(\hat{a}^l\) for \(l=2,3,\dots,L\).
Thereafter we compute the ouput error \(\hat{\delta}^L\) by computing all
Then we compute the back propagate error for each \(l=L-1,L-2,\dots,2\) as
Finally, we update the weights and the biases using gradient descent for each \(l=L-1,L-2,\dots,2\) and update the weights and biases according to the rules
The parameter \(\eta\) is the learning parameter discussed in connection with the gradient descent methods. Here it is convenient to use stochastic gradient descent (see the examples below) with mini-batches with an outer loop that steps through multiple epochs of training.
13.6. Setting up a Multi-layer perceptron model for classification¶
We are now gong to develop an example based on the MNIST data base. This is a classification problem and we need to use our cross-entropy function we discussed in connection with logistic regression. The cross-entropy defines our cost function for the classificaton problems with neural networks.
In binary classification with two classes \((0, 1)\) we define the logistic/sigmoid function as the probability that a particular input is in class \(0\) or \(1\). This is possible because the logistic function takes any input from the real numbers and inputs a number between 0 and 1, and can therefore be interpreted as a probability. It also has other nice properties, such as a derivative that is simple to calculate.
For an input \(\boldsymbol{a}\) from the hidden layer, the probability that the input \(\boldsymbol{x}\) is in class 0 or 1 is just. We let \(\theta\) represent the unknown weights and biases to be adjusted by our equations). The variable \(x\) represents our activation values \(z\). We have
and
where \(y \in \{0, 1\}\) and \(\hat{\theta}\) represents the weights and biases of our network.
Our cost function is given as (see the Logistic regression lectures)
This last equality means that we can interpret our cost function as a sum over the loss function
for each point in the dataset \(\mathcal{L}_i(\hat{\theta})\).
The negative sign is just so that we can think about our algorithm as minimizing a positive number, rather
than maximizing a negative number.
In multiclass classification it is common to treat each integer label as a so called one-hot vector:
\(y = 5 \quad \rightarrow \quad \hat{y} = (0, 0, 0, 0, 0, 1, 0, 0, 0, 0) ,\) and
\(y = 1 \quad \rightarrow \quad \hat{y} = (0, 1, 0, 0, 0, 0, 0, 0, 0, 0) ,\)
i.e. a binary bit string of length \(C\), where \(C = 10\) is the number of classes in the MNIST dataset (numbers from \(0\) to \(9\))..
If \(\hat{x}_i\) is the \(i\)-th input (image), \(y_{ic}\) refers to the \(c\)-th component of the \(i\)-th
output vector \(\hat{y}_i\).
The probability of \(\hat{x}_i\) being in class \(c\) will be given by the softmax function:
which reduces to the logistic function in the binary case.
The likelihood of this \(C\)-class classifier
is now given as:
Again we take the negative log-likelihood to define our cost function:
See the logistic regression lectures for a full definition of the cost function.
The back propagation equations need now only a small change, namely the definition of a new cost function. We are thus ready to use the same equations as before!
13.6.1. Example: binary classification problem¶
As an example of the above, relevant for project 2 as well, let us consider a binary class. As discussed in our logistic regression lectures, we defined a cost function in terms of the parameters \(\beta\) as
where we had defined the logistic (sigmoid) function
and
The parameters \(\hat{\beta}\) were defined using a minimization method like gradient descent or Newton-Raphson’s method.
Now we replace \(x_i\) with the activation \(z_i^l\) for a given layer \(l\) and the outputs as \(y_i=a_i^l=f(z_i^l)\), with \(z_i^l\) now being a function of the weights \(w_{ij}^l\) and biases \(b_i^l\). We have then
with
where the superscript \(l-1\) indicates that these are the outputs from layer \(l-1\). Our cost function at the final layer \(l=L\) is now
where we have defined the targets \(t_i\). The derivatives of the cost function with respect to the output \(a_i^L\) are then easily calculated and we get
In case we use another activation function than the logistic one, we need to evaluate other derivatives.
13.6.2. The Softmax function¶
In case we employ the more general case given by the Softmax equation, we need to evaluate the derivative of the activation function with respect to the activation \(z_i^l\), that is we need
For the Softmax function we have
Its derivative with respect to \(z_j^l\) gives
which in case of the simply binary model reduces to having \(i=j\).
13.6.3. Developing a code for doing neural networks with back propagation¶
One can identify a set of key steps when using neural networks to solve supervised learning problems:
Collect and pre-process data
Define model and architecture
Choose cost function and optimizer
Train the model
Evaluate model performance on test data
Adjust hyperparameters (if necessary, network architecture)
13.6.4. Collect and pre-process data¶
Here we will be using the MNIST dataset, which is readily available through the scikit-learn
package. You may also find it for example here.
The MNIST (Modified National Institute of Standards and Technology) database is a large database
of handwritten digits that is commonly used for training various image processing systems.
The MNIST dataset consists of 70 000 images of size \(28\times 28\) pixels, each labeled from 0 to 9.
The scikit-learn dataset we will use consists of a selection of 1797 images of size \(8\times 8\) collected and processed from this database.
To feed data into a feed-forward neural network we need to represent the inputs as a design/feature matrix \(X = (n_{inputs}, n_{features})\). Each row represents an input, in this case a handwritten digit, and each column represents a feature, in this case a pixel. The correct answers, also known as labels or targets are represented as a 1D array of integers \(Y = (n_{inputs}) = (5, 3, 1, 8,...)\).
As an example, say we want to build a neural network using supervised learning to predict Body-Mass Index (BMI) from
measurements of height (in m)
and weight (in kg). If we have measurements of 5 people the design/feature matrix could be for example:
and the targets would be:
Since each input image is a 2D matrix, we need to flatten the image (i.e. “unravel” the 2D matrix into a 1D array) to turn the data into a design/feature matrix. This means we lose all spatial information in the image, such as locality and translational invariance. More complicated architectures such as Convolutional Neural Networks can take advantage of such information, and are most commonly applied when analyzing images.
# import necessary packages
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# ensure the same random numbers appear every time
np.random.seed(0)
# display images in notebook
%matplotlib inline
plt.rcParams['figure.figsize'] = (12,12)
# download MNIST dataset
digits = datasets.load_digits()
# define inputs and labels
inputs = digits.images
labels = digits.target
print("inputs = (n_inputs, pixel_width, pixel_height) = " + str(inputs.shape))
print("labels = (n_inputs) = " + str(labels.shape))
# flatten the image
# the value -1 means dimension is inferred from the remaining dimensions: 8x8 = 64
n_inputs = len(inputs)
inputs = inputs.reshape(n_inputs, -1)
print("X = (n_inputs, n_features) = " + str(inputs.shape))
# choose some random images to display
indices = np.arange(n_inputs)
random_indices = np.random.choice(indices, size=5)
for i, image in enumerate(digits.images[random_indices]):
plt.subplot(1, 5, i+1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title("Label: %d" % digits.target[random_indices[i]])
plt.show()
inputs = (n_inputs, pixel_width, pixel_height) = (1797, 8, 8)
labels = (n_inputs) = (1797,)
X = (n_inputs, n_features) = (1797, 64)

13.6.5. Train and test datasets¶
Performing analysis before partitioning the dataset is a major error, that can lead to incorrect conclusions.
We will reserve \(80 \%\) of our dataset for training and \(20 \%\) for testing.
It is important that the train and test datasets are drawn randomly from our dataset, to ensure
no bias in the sampling.
Say you are taking measurements of weather data to predict the weather in the coming 5 days.
You don’t want to train your model on measurements taken from the hours 00.00 to 12.00, and then test it on data
collected from 12.00 to 24.00.
from sklearn.model_selection import train_test_split
# one-liner from scikit-learn library
train_size = 0.8
test_size = 1 - train_size
X_train, X_test, Y_train, Y_test = train_test_split(inputs, labels, train_size=train_size,
test_size=test_size)
# equivalently in numpy
def train_test_split_numpy(inputs, labels, train_size, test_size):
n_inputs = len(inputs)
inputs_shuffled = inputs.copy()
labels_shuffled = labels.copy()
np.random.shuffle(inputs_shuffled)
np.random.shuffle(labels_shuffled)
train_end = int(n_inputs*train_size)
X_train, X_test = inputs_shuffled[:train_end], inputs_shuffled[train_end:]
Y_train, Y_test = labels_shuffled[:train_end], labels_shuffled[train_end:]
return X_train, X_test, Y_train, Y_test
#X_train, X_test, Y_train, Y_test = train_test_split_numpy(inputs, labels, train_size, test_size)
print("Number of training images: " + str(len(X_train)))
print("Number of test images: " + str(len(X_test)))
Number of training images: 1437
Number of test images: 360
13.6.6. Define model and architecture¶
Our simple feed-forward neural network will consist of an input layer, a single hidden layer and an output layer. The activation \(y\) of each neuron is a weighted sum of inputs, passed through an activation function. In case of the simple perceptron model we have
where \(f\) is the activation function, \(a_i\) represents input from neuron \(i\) in the preceding layer
and \(w_i\) is the weight to input \(i\).
The activation of the neurons in the input layer is just the features (e.g. a pixel value).
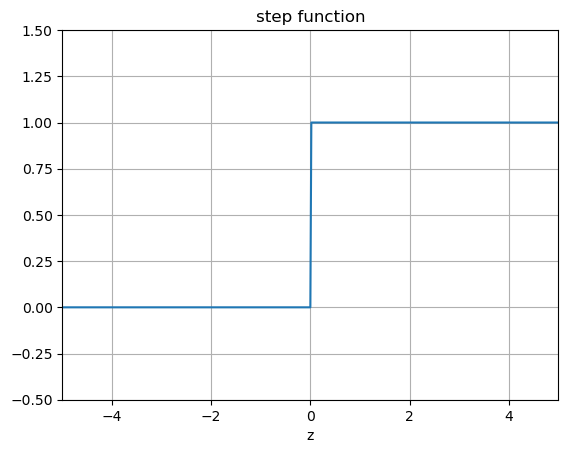
The simplest activation function for a neuron is the Heaviside function:
A feed-forward neural network with this activation is known as a perceptron.
For a binary classifier (i.e. two classes, 0 or 1, dog or not-dog) we can also use this in our output layer.
This activation can be generalized to \(k\) classes (using e.g. the one-against-all strategy),
and we call these architectures multiclass perceptrons.
However, it is now common to use the terms Single Layer Perceptron (SLP) (1 hidden layer) and
Multilayer Perceptron (MLP) (2 or more hidden layers) to refer to feed-forward neural networks with any activation function.
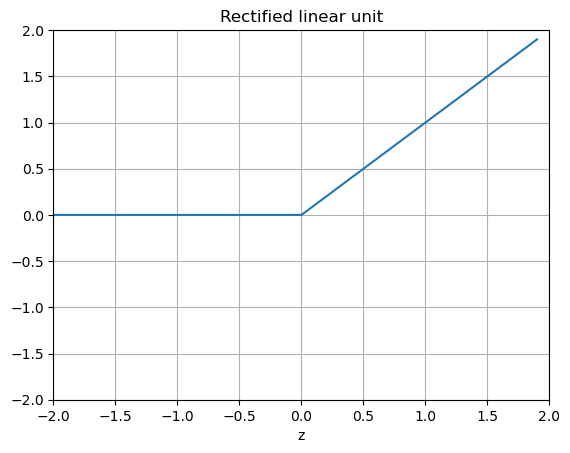
Typical choices for activation functions include the sigmoid function, hyperbolic tangent, and Rectified Linear Unit (ReLU).
We will be using the sigmoid function \(\sigma(x)\):
which is inspired by probability theory (see logistic regression) and was most commonly used until about 2011. See the discussion below concerning other activation functions.
13.6.7. Layers¶
Input
Since each input image has 8x8 = 64 pixels or features, we have an input layer of 64 neurons.
Hidden layer
We will use 50 neurons in the hidden layer receiving input from the neurons in the input layer.
Since each neuron in the hidden layer is connected to the 64 inputs we have 64x50 = 3200 weights to the hidden layer.
Output
If we were building a binary classifier, it would be sufficient with a single neuron in the output layer, which could output 0 or 1 according to the Heaviside function. This would be an example of a hard classifier, meaning it outputs the class of the input directly. However, if we are dealing with noisy data it is often beneficial to use a soft classifier, which outputs the probability of being in class 0 or 1.
For a soft binary classifier, we could use a single neuron and interpret the output as either being the probability of being in class 0 or the probability of being in class 1. Alternatively we could use 2 neurons, and interpret each neuron as the probability of being in each class.
Since we are doing multiclass classification, with 10 categories, it is natural to use 10 neurons in the output layer. We number the neurons \(j = 0,1,...,9\). The activation of each output neuron \(j\) will be according to the softmax function:
i.e. each neuron \(j\) outputs the probability of being in class \(j\) given an input from the hidden layer \(\hat{a}\), with \(\hat{w}_j\) the weights of neuron \(j\) to the inputs.
The denominator is a normalization factor to ensure the outputs (probabilities) sum up to 1.
The exponent is just the weighted sum of inputs as before:
Since each neuron in the output layer is connected to the 50 inputs from the hidden layer we have 50x10 = 500 weights to the output layer.
13.6.8. Weights and biases¶
Typically weights are initialized with small values distributed around zero, drawn from a uniform or normal distribution. Setting all weights to zero means all neurons give the same output, making the network useless.
Adding a bias value to the weighted sum of inputs allows the neural network to represent a greater range of values. Without it, any input with the value 0 will be mapped to zero (before being passed through the activation). The bias unit has an output of 1, and a weight to each neuron \(j\), \(b_j\):
The bias weights \(\hat{b}\) are often initialized to zero, but a small value like \(0.01\) ensures all neurons have some output which can be backpropagated in the first training cycle.
# building our neural network
n_inputs, n_features = X_train.shape
n_hidden_neurons = 50
n_categories = 10
# we make the weights normally distributed using numpy.random.randn
# weights and bias in the hidden layer
hidden_weights = np.random.randn(n_features, n_hidden_neurons)
hidden_bias = np.zeros(n_hidden_neurons) + 0.01
# weights and bias in the output layer
output_weights = np.random.randn(n_hidden_neurons, n_categories)
output_bias = np.zeros(n_categories) + 0.01
13.6.9. Feed-forward pass¶
Denote \(F\) the number of features, \(H\) the number of hidden neurons and \(C\) the number of categories.
For each input image we calculate a weighted sum of input features (pixel values) to each neuron \(j\) in the hidden layer \(l\):
this is then passed through our activation function
We calculate a weighted sum of inputs (activations in the hidden layer) to each neuron \(j\) in the output layer:
Finally we calculate the output of neuron \(j\) in the output layer using the softmax function:
13.6.10. Matrix multiplications¶
Since our data has the dimensions \(X = (n_{inputs}, n_{features})\) and our weights to the hidden
layer have the dimensions
\(W_{hidden} = (n_{features}, n_{hidden})\),
we can easily feed the network all our training data in one go by taking the matrix product
and obtain a matrix that holds the weighted sum of inputs to the hidden layer
for each input image and each hidden neuron.
We also add the bias to obtain a matrix of weighted sums to the hidden layer \(Z^{h}\):
meaning the same bias (1D array with size equal number of hidden neurons) is added to each input image.
This is then passed through the activation:
This is fed to the output layer:
Finally we receive our output values for each image and each category by passing it through the softmax function:
# setup the feed-forward pass, subscript h = hidden layer
def sigmoid(x):
return 1/(1 + np.exp(-x))
def feed_forward(X):
# weighted sum of inputs to the hidden layer
z_h = np.matmul(X, hidden_weights) + hidden_bias
# activation in the hidden layer
a_h = sigmoid(z_h)
# weighted sum of inputs to the output layer
z_o = np.matmul(a_h, output_weights) + output_bias
# softmax output
# axis 0 holds each input and axis 1 the probabilities of each category
exp_term = np.exp(z_o)
probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
return probabilities
probabilities = feed_forward(X_train)
print("probabilities = (n_inputs, n_categories) = " + str(probabilities.shape))
print("probability that image 0 is in category 0,1,2,...,9 = \n" + str(probabilities[0]))
print("probabilities sum up to: " + str(probabilities[0].sum()))
print()
# we obtain a prediction by taking the class with the highest likelihood
def predict(X):
probabilities = feed_forward(X)
return np.argmax(probabilities, axis=1)
predictions = predict(X_train)
print("predictions = (n_inputs) = " + str(predictions.shape))
print("prediction for image 0: " + str(predictions[0]))
print("correct label for image 0: " + str(Y_train[0]))
probabilities = (n_inputs, n_categories) = (1437, 10)
probability that image 0 is in category 0,1,2,...,9 =
[5.41511965e-04 2.17174962e-03 8.84355903e-03 1.44970586e-03
1.10378326e-04 5.08318298e-09 2.03256632e-04 1.92507116e-03
9.84443254e-01 3.11507992e-04]
probabilities sum up to: 1.0
predictions = (n_inputs) = (1437,)
prediction for image 0: 8
correct label for image 0: 6
13.6.11. Choose cost function and optimizer¶
To measure how well our neural network is doing we need to introduce a cost function.
We will call the function that gives the error of a single sample output the loss function, and the function
that gives the total error of our network across all samples the cost function.
A typical choice for multiclass classification is the cross-entropy loss, also known as the negative log likelihood.
In multiclass classification it is common to treat each integer label as a so called one-hot vector:
i.e. a binary bit string of length \(C\), where \(C = 10\) is the number of classes in the MNIST dataset.
Let \(y_{ic}\) denote the \(c\)-th component of the \(i\)-th one-hot vector.
We define the cost function \(\mathcal{C}\) as a sum over the cross-entropy loss for each point \(\hat{x}_i\) in the dataset.
In the one-hot representation only one of the terms in the loss function is non-zero, namely the
probability of the correct category \(c'\)
(i.e. the category \(c'\) such that \(y_{ic'} = 1\)). This means that the cross entropy loss only punishes you for how wrong
you got the correct label. The probability of category \(c\) is given by the softmax function. The vector \(\hat{\theta}\) represents the parameters of our network, i.e. all the weights and biases.
13.6.12. Optimizing the cost function¶
The network is trained by finding the weights and biases that minimize the cost function. One of the most widely used classes of methods is gradient descent and its generalizations. The idea behind gradient descent
is simply to adjust the weights in the direction where the gradient of the cost function is large and negative. This ensures we flow toward a local minimum of the cost function.
Each parameter \(\theta\) is iteratively adjusted according to the rule
where \(\eta\) is known as the learning rate, which controls how big a step we take towards the minimum.
This update can be repeated for any number of iterations, or until we are satisfied with the result.
A simple and effective improvement is a variant called Batch Gradient Descent.
Instead of calculating the gradient on the whole dataset, we calculate an approximation of the gradient
on a subset of the data called a minibatch.
If there are \(N\) data points and we have a minibatch size of \(M\), the total number of batches
is \(N/M\).
We denote each minibatch \(B_k\), with \(k = 1, 2,...,N/M\). The gradient then becomes:
i.e. instead of averaging the loss over the entire dataset, we average over a minibatch.
This has two important benefits:
Introducing stochasticity decreases the chance that the algorithm becomes stuck in a local minima.
It significantly speeds up the calculation, since we do not have to use the entire dataset to calculate the gradient.
The various optmization methods, with codes and algorithms, are discussed in our lectures on Gradient descent approaches.
13.6.13. Regularization¶
It is common to add an extra term to the cost function, proportional to the size of the weights. This is equivalent to constraining the size of the weights, so that they do not grow out of control. Constraining the size of the weights means that the weights cannot grow arbitrarily large to fit the training data, and in this way reduces overfitting.
We will measure the size of the weights using the so called L2-norm, meaning our cost function becomes:
i.e. we sum up all the weights squared. The factor \(\lambda\) is known as a regularization parameter.
In order to train the model, we need to calculate the derivative of the cost function with respect to every bias and weight in the network. In total our network has \((64 + 1)\times 50=3250\) weights in the hidden layer and \((50 + 1)\times 10=510\) weights to the output layer (\(+1\) for the bias), and the gradient must be calculated for every parameter. We use the backpropagation algorithm discussed above. This is a clever use of the chain rule that allows us to calculate the gradient efficently.
13.6.14. Matrix multiplication¶
To more efficently train our network these equations are implemented using matrix operations.
The error in the output layer is calculated simply as, with \(\hat{t}\) being our targets,
The gradient for the output weights is calculated as
where \(\hat{a} = (n_{inputs}, n_{hidden})\). This simply means that we are summing up the gradients for each input.
Since we are going backwards we have to transpose the activation matrix.
The gradient with respect to the output bias is then
The error in the hidden layer is
where \(f'(a_{h})\) is the derivative of the activation in the hidden layer. The matrix products mean that we are summing up the products for each neuron in the output layer. The symbol \(\circ\) denotes the Hadamard product, meaning element-wise multiplication.
This again gives us the gradients in the hidden layer:
# to categorical turns our integer vector into a onehot representation
from sklearn.metrics import accuracy_score
# one-hot in numpy
def to_categorical_numpy(integer_vector):
n_inputs = len(integer_vector)
n_categories = np.max(integer_vector) + 1
onehot_vector = np.zeros((n_inputs, n_categories))
onehot_vector[range(n_inputs), integer_vector] = 1
return onehot_vector
#Y_train_onehot, Y_test_onehot = to_categorical(Y_train), to_categorical(Y_test)
Y_train_onehot, Y_test_onehot = to_categorical_numpy(Y_train), to_categorical_numpy(Y_test)
def feed_forward_train(X):
# weighted sum of inputs to the hidden layer
z_h = np.matmul(X, hidden_weights) + hidden_bias
# activation in the hidden layer
a_h = sigmoid(z_h)
# weighted sum of inputs to the output layer
z_o = np.matmul(a_h, output_weights) + output_bias
# softmax output
# axis 0 holds each input and axis 1 the probabilities of each category
exp_term = np.exp(z_o)
probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
# for backpropagation need activations in hidden and output layers
return a_h, probabilities
def backpropagation(X, Y):
a_h, probabilities = feed_forward_train(X)
# error in the output layer
error_output = probabilities - Y
# error in the hidden layer
error_hidden = np.matmul(error_output, output_weights.T) * a_h * (1 - a_h)
# gradients for the output layer
output_weights_gradient = np.matmul(a_h.T, error_output)
output_bias_gradient = np.sum(error_output, axis=0)
# gradient for the hidden layer
hidden_weights_gradient = np.matmul(X.T, error_hidden)
hidden_bias_gradient = np.sum(error_hidden, axis=0)
return output_weights_gradient, output_bias_gradient, hidden_weights_gradient, hidden_bias_gradient
print("Old accuracy on training data: " + str(accuracy_score(predict(X_train), Y_train)))
eta = 0.01
lmbd = 0.01
for i in range(1000):
# calculate gradients
dWo, dBo, dWh, dBh = backpropagation(X_train, Y_train_onehot)
# regularization term gradients
dWo += lmbd * output_weights
dWh += lmbd * hidden_weights
# update weights and biases
output_weights -= eta * dWo
output_bias -= eta * dBo
hidden_weights -= eta * dWh
hidden_bias -= eta * dBh
print("New accuracy on training data: " + str(accuracy_score(predict(X_train), Y_train)))
Old accuracy on training data: 0.1440501043841336
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
New accuracy on training data: 0.09951287404314545
13.6.15. Improving performance¶
As we can see the network does not seem to be learning at all. It seems to be just guessing the label for each image.
In order to obtain a network that does something useful, we will have to do a bit more work.
The choice of hyperparameters such as learning rate and regularization parameter is hugely influential for the performance of the network. Typically a grid-search is performed, wherein we test different hyperparameters separated by orders of magnitude. For example we could test the learning rates \(\eta = 10^{-6}, 10^{-5},...,10^{-1}\) with different regularization parameters \(\lambda = 10^{-6},...,10^{-0}\).
Next, we haven’t implemented minibatching yet, which introduces stochasticity and is though to act as an important regularizer on the weights. We call a feed-forward + backward pass with a minibatch an iteration, and a full training period going through the entire dataset (\(n/M\) batches) an epoch.
If this does not improve network performance, you may want to consider altering the network architecture, adding more neurons or hidden layers.
Andrew Ng goes through some of these considerations in this video. You can find a summary of the video here.
13.6.16. Full object-oriented implementation¶
It is very natural to think of the network as an object, with specific instances of the network being realizations of this object with different hyperparameters. An implementation using Python classes provides a clean structure and interface, and the full implementation of our neural network is given below.
class NeuralNetwork:
def __init__(
self,
X_data,
Y_data,
n_hidden_neurons=50,
n_categories=10,
epochs=10,
batch_size=100,
eta=0.1,
lmbd=0.0):
self.X_data_full = X_data
self.Y_data_full = Y_data
self.n_inputs = X_data.shape[0]
self.n_features = X_data.shape[1]
self.n_hidden_neurons = n_hidden_neurons
self.n_categories = n_categories
self.epochs = epochs
self.batch_size = batch_size
self.iterations = self.n_inputs // self.batch_size
self.eta = eta
self.lmbd = lmbd
self.create_biases_and_weights()
def create_biases_and_weights(self):
self.hidden_weights = np.random.randn(self.n_features, self.n_hidden_neurons)
self.hidden_bias = np.zeros(self.n_hidden_neurons) + 0.01
self.output_weights = np.random.randn(self.n_hidden_neurons, self.n_categories)
self.output_bias = np.zeros(self.n_categories) + 0.01
def feed_forward(self):
# feed-forward for training
self.z_h = np.matmul(self.X_data, self.hidden_weights) + self.hidden_bias
self.a_h = sigmoid(self.z_h)
self.z_o = np.matmul(self.a_h, self.output_weights) + self.output_bias
exp_term = np.exp(self.z_o)
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
def feed_forward_out(self, X):
# feed-forward for output
z_h = np.matmul(X, self.hidden_weights) + self.hidden_bias
a_h = sigmoid(z_h)
z_o = np.matmul(a_h, self.output_weights) + self.output_bias
exp_term = np.exp(z_o)
probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
return probabilities
def backpropagation(self):
error_output = self.probabilities - self.Y_data
error_hidden = np.matmul(error_output, self.output_weights.T) * self.a_h * (1 - self.a_h)
self.output_weights_gradient = np.matmul(self.a_h.T, error_output)
self.output_bias_gradient = np.sum(error_output, axis=0)
self.hidden_weights_gradient = np.matmul(self.X_data.T, error_hidden)
self.hidden_bias_gradient = np.sum(error_hidden, axis=0)
if self.lmbd > 0.0:
self.output_weights_gradient += self.lmbd * self.output_weights
self.hidden_weights_gradient += self.lmbd * self.hidden_weights
self.output_weights -= self.eta * self.output_weights_gradient
self.output_bias -= self.eta * self.output_bias_gradient
self.hidden_weights -= self.eta * self.hidden_weights_gradient
self.hidden_bias -= self.eta * self.hidden_bias_gradient
def predict(self, X):
probabilities = self.feed_forward_out(X)
return np.argmax(probabilities, axis=1)
def predict_probabilities(self, X):
probabilities = self.feed_forward_out(X)
return probabilities
def train(self):
data_indices = np.arange(self.n_inputs)
for i in range(self.epochs):
for j in range(self.iterations):
# pick datapoints with replacement
chosen_datapoints = np.random.choice(
data_indices, size=self.batch_size, replace=False
)
# minibatch training data
self.X_data = self.X_data_full[chosen_datapoints]
self.Y_data = self.Y_data_full[chosen_datapoints]
self.feed_forward()
self.backpropagation()
13.6.17. Evaluate model performance on test data¶
To measure the performance of our network we evaluate how well it does it data it has never seen before, i.e. the test data.
We measure the performance of the network using the accuracy score.
The accuracy is as you would expect just the number of images correctly labeled divided by the total number of images. A perfect classifier will have an accuracy score of \(1\).
where \(I\) is the indicator function, \(1\) if \(\hat{y}_i = y_i\) and \(0\) otherwise.
epochs = 100
batch_size = 100
dnn = NeuralNetwork(X_train, Y_train_onehot, eta=eta, lmbd=lmbd, epochs=epochs, batch_size=batch_size,
n_hidden_neurons=n_hidden_neurons, n_categories=n_categories)
dnn.train()
test_predict = dnn.predict(X_test)
# accuracy score from scikit library
print("Accuracy score on test set: ", accuracy_score(Y_test, test_predict))
# equivalent in numpy
def accuracy_score_numpy(Y_test, Y_pred):
return np.sum(Y_test == Y_pred) / len(Y_test)
#print("Accuracy score on test set: ", accuracy_score_numpy(Y_test, test_predict))
Accuracy score on test set: 0.9444444444444444
13.6.18. Adjust hyperparameters¶
We now perform a grid search to find the optimal hyperparameters for the network.
Note that we are only using 1 layer with 50 neurons, and human performance is estimated to be around \(98\%\) (\(2\%\) error rate).
eta_vals = np.logspace(-5, 1, 7)
lmbd_vals = np.logspace(-5, 1, 7)
# store the models for later use
DNN_numpy = np.zeros((len(eta_vals), len(lmbd_vals)), dtype=object)
# grid search
for i, eta in enumerate(eta_vals):
for j, lmbd in enumerate(lmbd_vals):
dnn = NeuralNetwork(X_train, Y_train_onehot, eta=eta, lmbd=lmbd, epochs=epochs, batch_size=batch_size,
n_hidden_neurons=n_hidden_neurons, n_categories=n_categories)
dnn.train()
DNN_numpy[i][j] = dnn
test_predict = dnn.predict(X_test)
print("Learning rate = ", eta)
print("Lambda = ", lmbd)
print("Accuracy score on test set: ", accuracy_score(Y_test, test_predict))
print()
Learning rate = 1e-05
Lambda = 1e-05
Accuracy score on test set: 0.11666666666666667
Learning rate = 1e-05
Lambda = 0.0001
Accuracy score on test set: 0.20833333333333334
Learning rate = 1e-05
Lambda = 0.001
Accuracy score on test set: 0.12222222222222222
Learning rate = 1e-05
Lambda = 0.01
Accuracy score on test set: 0.14722222222222223
Learning rate = 1e-05
Lambda = 0.1
Accuracy score on test set: 0.17777777777777778
Learning rate = 1e-05
Lambda = 1.0
Accuracy score on test set: 0.16111111111111112
Learning rate = 1e-05
Lambda = 10.0
Accuracy score on test set: 0.20277777777777778
Learning rate = 0.0001
Lambda = 1e-05
Accuracy score on test set: 0.5305555555555556
Learning rate = 0.0001
Lambda = 0.0001
Accuracy score on test set: 0.5944444444444444
Learning rate = 0.0001
Lambda = 0.001
Accuracy score on test set: 0.5888888888888889
Learning rate = 0.0001
Lambda = 0.01
Accuracy score on test set: 0.6111111111111112
Learning rate = 0.0001
Lambda = 0.1
Accuracy score on test set: 0.5222222222222223
Learning rate = 0.0001
Lambda = 1.0
Accuracy score on test set: 0.5555555555555556
Learning rate = 0.0001
Lambda = 10.0
Accuracy score on test set: 0.8055555555555556
Learning rate = 0.001
Lambda = 1e-05
Accuracy score on test set: 0.85
Learning rate = 0.001
Lambda = 0.0001
Accuracy score on test set: 0.85
Learning rate = 0.001
Lambda = 0.001
Accuracy score on test set: 0.875
Learning rate = 0.001
Lambda = 0.01
Accuracy score on test set: 0.8666666666666667
Learning rate = 0.001
Lambda = 0.1
Accuracy score on test set: 0.8638888888888889
Learning rate = 0.001
Lambda = 1.0
Accuracy score on test set: 0.9555555555555556
Learning rate = 0.001
Lambda = 10.0
Accuracy score on test set: 0.925
Learning rate = 0.01
Lambda = 1e-05
Accuracy score on test set: 0.9472222222222222
Learning rate = 0.01
Lambda = 0.0001
Accuracy score on test set: 0.9277777777777778
Learning rate = 0.01
Lambda = 0.001
Accuracy score on test set: 0.9472222222222222
Learning rate = 0.01
Lambda = 0.01
Accuracy score on test set: 0.9305555555555556
Learning rate = 0.01
Lambda = 0.1
Accuracy score on test set: 0.9555555555555556
Learning rate = 0.01
Lambda = 1.0
Accuracy score on test set: 0.7694444444444445
Learning rate = 0.01
Lambda = 10.0
Accuracy score on test set: 0.19166666666666668
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 0.1
Lambda = 1e-05
Accuracy score on test set: 0.10555555555555556
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 0.1
Lambda = 0.0001
Accuracy score on test set: 0.08611111111111111
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 0.1
Lambda = 0.001
Accuracy score on test set: 0.10555555555555556
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 0.1
Lambda = 0.01
Accuracy score on test set: 0.08888888888888889
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 0.1
Lambda = 0.1
Accuracy score on test set: 0.08611111111111111
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 0.1
Lambda = 1.0
Accuracy score on test set: 0.08888888888888889
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 0.1
Lambda = 10.0
Accuracy score on test set: 0.09166666666666666
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 1.0
Lambda = 1e-05
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 1.0
Lambda = 0.0001
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 1.0
Lambda = 0.001
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 1.0
Lambda = 0.01
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 1.0
Lambda = 0.1
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
Learning rate = 1.0
Lambda = 1.0
Accuracy score on test set: 0.10555555555555556
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 1.0
Lambda = 10.0
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 10.0
Lambda = 1e-05
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 10.0
Lambda = 0.0001
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 10.0
Lambda = 0.001
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 10.0
Lambda = 0.01
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 10.0
Lambda = 0.1
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 10.0
Lambda = 1.0
Accuracy score on test set: 0.07777777777777778
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:43: RuntimeWarning: overflow encountered in exp
exp_term = np.exp(self.z_o)
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/1630775253.py:44: RuntimeWarning: invalid value encountered in true_divide
self.probabilities = exp_term / np.sum(exp_term, axis=1, keepdims=True)
Learning rate = 10.0
Lambda = 10.0
Accuracy score on test set: 0.07777777777777778
13.6.19. Visualization¶
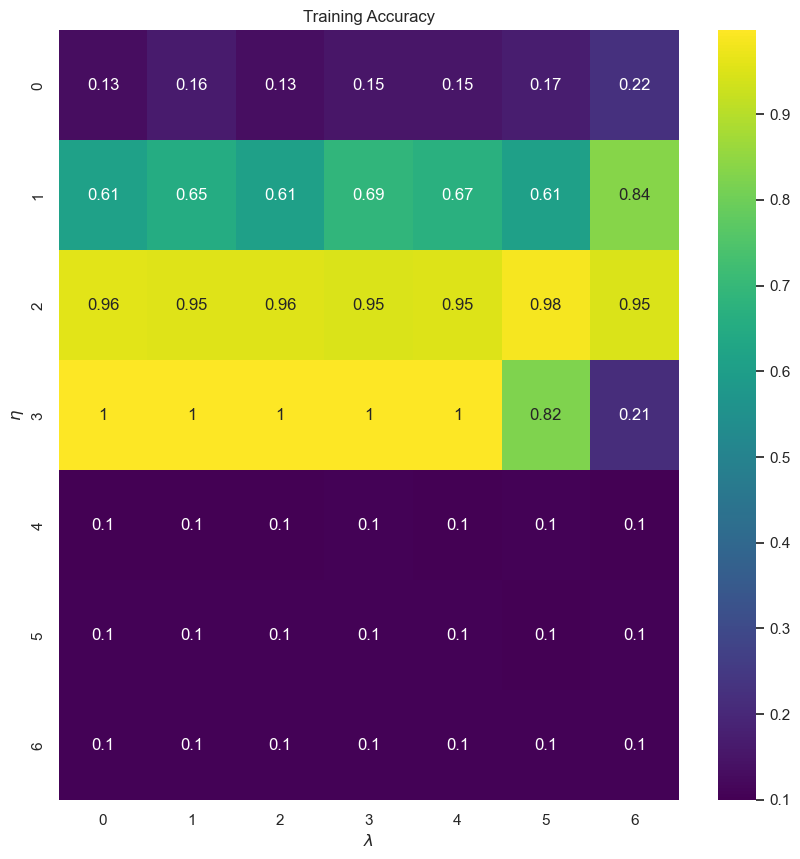
# visual representation of grid search
# uses seaborn heatmap, you can also do this with matplotlib imshow
import seaborn as sns
sns.set()
train_accuracy = np.zeros((len(eta_vals), len(lmbd_vals)))
test_accuracy = np.zeros((len(eta_vals), len(lmbd_vals)))
for i in range(len(eta_vals)):
for j in range(len(lmbd_vals)):
dnn = DNN_numpy[i][j]
train_pred = dnn.predict(X_train)
test_pred = dnn.predict(X_test)
train_accuracy[i][j] = accuracy_score(Y_train, train_pred)
test_accuracy[i][j] = accuracy_score(Y_test, test_pred)
fig, ax = plt.subplots(figsize = (10, 10))
sns.heatmap(train_accuracy, annot=True, ax=ax, cmap="viridis")
ax.set_title("Training Accuracy")
ax.set_ylabel("$\eta$")
ax.set_xlabel("$\lambda$")
plt.show()
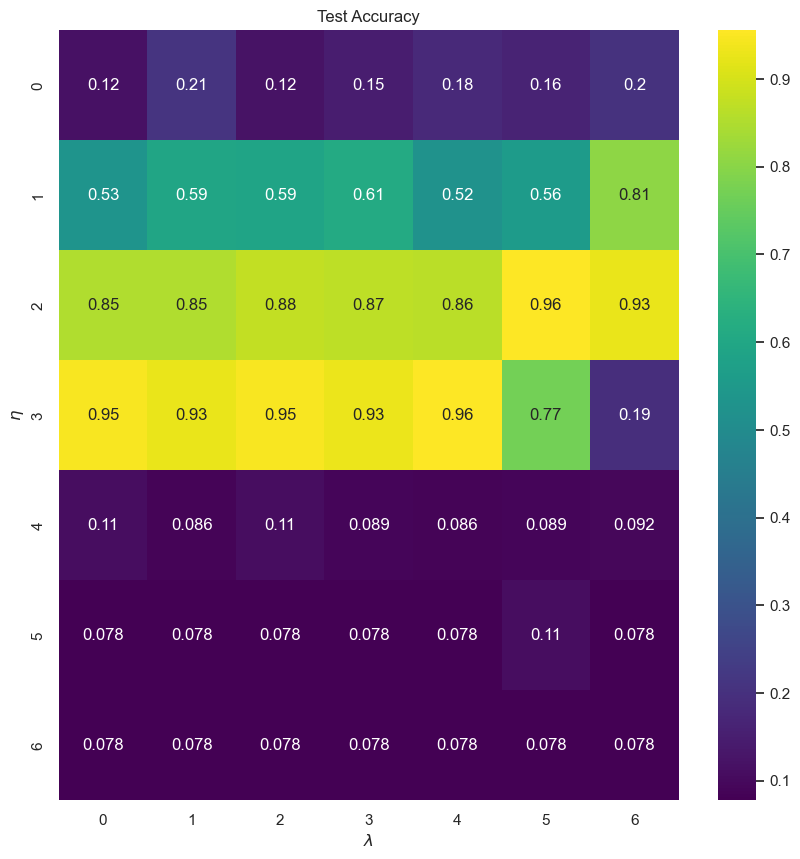
fig, ax = plt.subplots(figsize = (10, 10))
sns.heatmap(test_accuracy, annot=True, ax=ax, cmap="viridis")
ax.set_title("Test Accuracy")
ax.set_ylabel("$\eta$")
ax.set_xlabel("$\lambda$")
plt.show()
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
/var/folders/td/3yk470mj5p931p9dtkk0y6jw0000gn/T/ipykernel_67844/953065564.py:4: RuntimeWarning: overflow encountered in exp
return 1/(1 + np.exp(-x))
13.6.20. scikit-learn implementation¶
scikit-learn focuses more on traditional machine learning methods, such as regression, clustering, decision trees, etc. As such, it has only two types of neural networks: Multi Layer Perceptron outputting continuous values, MPLRegressor, and Multi Layer Perceptron outputting labels, MLPClassifier. We will see how simple it is to use these classes.
scikit-learn implements a few improvements from our neural network, such as early stopping, a varying learning rate, different optimization methods, etc. We would therefore expect a better performance overall.
from sklearn.neural_network import MLPClassifier
# store models for later use
DNN_scikit = np.zeros((len(eta_vals), len(lmbd_vals)), dtype=object)
for i, eta in enumerate(eta_vals):
for j, lmbd in enumerate(lmbd_vals):
dnn = MLPClassifier(hidden_layer_sizes=(n_hidden_neurons), activation='logistic',
alpha=lmbd, learning_rate_init=eta, max_iter=epochs)
dnn.fit(X_train, Y_train)
DNN_scikit[i][j] = dnn
print("Learning rate = ", eta)
print("Lambda = ", lmbd)
print("Accuracy score on test set: ", dnn.score(X_test, Y_test))
print()
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 1e-05
Lambda = 1e-05
Accuracy score on test set: 0.18333333333333332
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 1e-05
Lambda = 0.0001
Accuracy score on test set: 0.18611111111111112
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 1e-05
Lambda = 0.001
Accuracy score on test set: 0.13055555555555556
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 1e-05
Lambda = 0.01
Accuracy score on test set: 0.24444444444444444
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 1e-05
Lambda = 0.1
Accuracy score on test set: 0.23333333333333334
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 1e-05
Lambda = 1.0
Accuracy score on test set: 0.12777777777777777
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 1e-05
Lambda = 10.0
Accuracy score on test set: 0.1527777777777778
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.0001
Lambda = 1e-05
Accuracy score on test set: 0.9111111111111111
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.0001
Lambda = 0.0001
Accuracy score on test set: 0.8888888888888888
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.0001
Lambda = 0.001
Accuracy score on test set: 0.8722222222222222
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.0001
Lambda = 0.01
Accuracy score on test set: 0.8305555555555556
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.0001
Lambda = 0.1
Accuracy score on test set: 0.8888888888888888
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.0001
Lambda = 1.0
Accuracy score on test set: 0.8805555555555555
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.0001
Lambda = 10.0
Accuracy score on test set: 0.8944444444444445
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.001
Lambda = 1e-05
Accuracy score on test set: 0.975
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.001
Lambda = 0.0001
Accuracy score on test set: 0.9777777777777777
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.001
Lambda = 0.001
Accuracy score on test set: 0.9805555555555555
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.001
Lambda = 0.01
Accuracy score on test set: 0.9861111111111112
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.001
Lambda = 0.1
Accuracy score on test set: 0.9805555555555555
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.001
Lambda = 1.0
Accuracy score on test set: 0.9777777777777777
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.001
Lambda = 10.0
Accuracy score on test set: 0.9444444444444444
/Users/mhjensen/miniforge3/envs/myenv/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:692: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (100) reached and the optimization hasn't converged yet.
warnings.warn(
Learning rate = 0.01
Lambda = 1e-05
Accuracy score on test set: 0.9861111111111112
Learning rate = 0.01
Lambda = 0.0001
Accuracy score on test set: 0.9888888888888889
Learning rate = 0.01
Lambda = 0.001
Accuracy score on test set: 0.9888888888888889
Learning rate = 0.01
Lambda = 0.01
Accuracy score on test set: 0.9861111111111112
Learning rate = 0.01
Lambda = 0.1
Accuracy score on test set: 0.9888888888888889
Learning rate = 0.01
Lambda = 1.0
Accuracy score on test set: 0.9722222222222222
Learning rate = 0.01
Lambda = 10.0
Accuracy score on test set: 0.9527777777777777
Learning rate = 0.1
Lambda = 1e-05
Accuracy score on test set: 0.9027777777777778
Learning rate = 0.1
Lambda = 0.0001
Accuracy score on test set: 0.8583333333333333
Learning rate = 0.1
Lambda = 0.001
Accuracy score on test set: 0.8722222222222222
Learning rate = 0.1
Lambda = 0.01
Accuracy score on test set: 0.9055555555555556
Learning rate = 0.1
Lambda = 0.1
Accuracy score on test set: 0.8805555555555555
Learning rate = 0.1
Lambda = 1.0
Accuracy score on test set: 0.8722222222222222
Learning rate = 0.1
Lambda = 10.0
Accuracy score on test set: 0.8666666666666667
Learning rate = 1.0
Lambda = 1e-05
Accuracy score on test set: 0.08611111111111111
Learning rate = 1.0
Lambda = 0.0001
Accuracy score on test set: 0.10555555555555556
Learning rate = 1.0
Lambda = 0.001
Accuracy score on test set: 0.10555555555555556
Learning rate = 1.0
Lambda = 0.01
Accuracy score on test set: 0.17777777777777778
Learning rate = 1.0
Lambda = 0.1
Accuracy score on test set: 0.08333333333333333
Learning rate = 1.0
Lambda = 1.0
Accuracy score on test set: 0.08888888888888889
Learning rate = 1.0
Lambda = 10.0
Accuracy score on test set: 0.09444444444444444
Learning rate = 10.0
Lambda = 1e-05
Accuracy score on test set: 0.17222222222222222
Learning rate = 10.0
Lambda = 0.0001
Accuracy score on test set: 0.11666666666666667
Learning rate = 10.0
Lambda = 0.001
Accuracy score on test set: 0.10555555555555556
Learning rate = 10.0
Lambda = 0.01
Accuracy score on test set: 0.1388888888888889
Learning rate = 10.0
Lambda = 0.1
Accuracy score on test set: 0.11388888888888889
Learning rate = 10.0
Lambda = 1.0
Accuracy score on test set: 0.10555555555555556
Learning rate = 10.0
Lambda = 10.0
Accuracy score on test set: 0.09444444444444444
13.6.21. Visualization¶
# optional
# visual representation of grid search
# uses seaborn heatmap, could probably do this in matplotlib
import seaborn as sns
sns.set()
train_accuracy = np.zeros((len(eta_vals), len(lmbd_vals)))
test_accuracy = np.zeros((len(eta_vals), len(lmbd_vals)))
for i in range(len(eta_vals)):
for j in range(len(lmbd_vals)):
dnn = DNN_scikit[i][j]
train_pred = dnn.predict(X_train)
test_pred = dnn.predict(X_test)
train_accuracy[i][j] = accuracy_score(Y_train, train_pred)
test_accuracy[i][j] = accuracy_score(Y_test, test_pred)
fig, ax = plt.subplots(figsize = (10, 10))
sns.heatmap(train_accuracy, annot=True, ax=ax, cmap="viridis")
ax.set_title("Training Accuracy")
ax.set_ylabel("$\eta$")
ax.set_xlabel("$\lambda$")
plt.show()
fig, ax = plt.subplots(figsize = (10, 10))
sns.heatmap(test_accuracy, annot=True, ax=ax, cmap="viridis")
ax.set_title("Test Accuracy")
ax.set_ylabel("$\eta$")
ax.set_xlabel("$\lambda$")
plt.show()
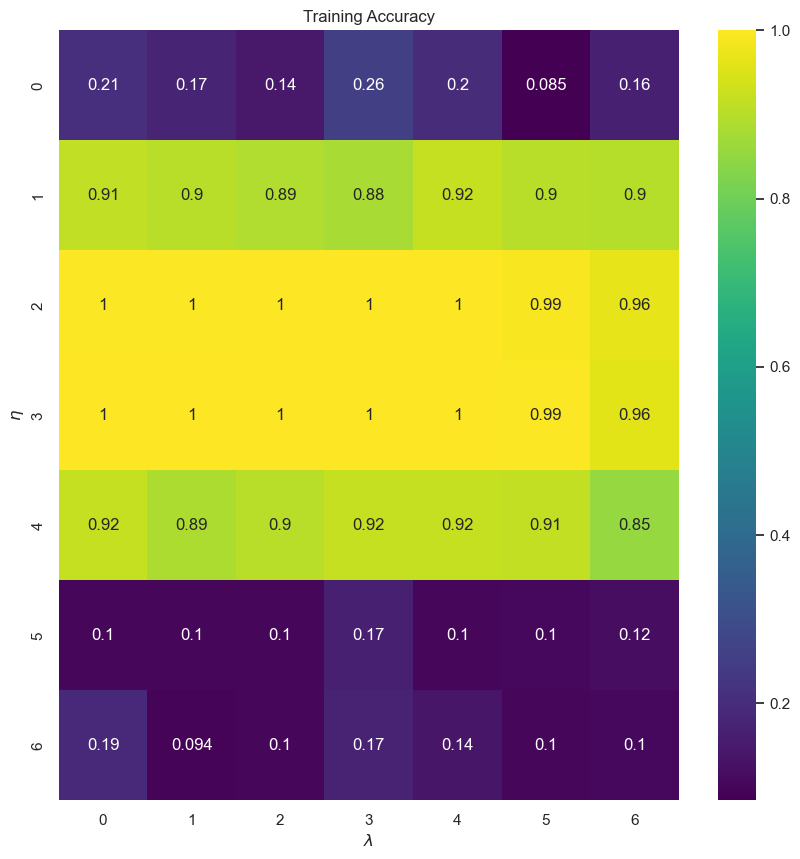
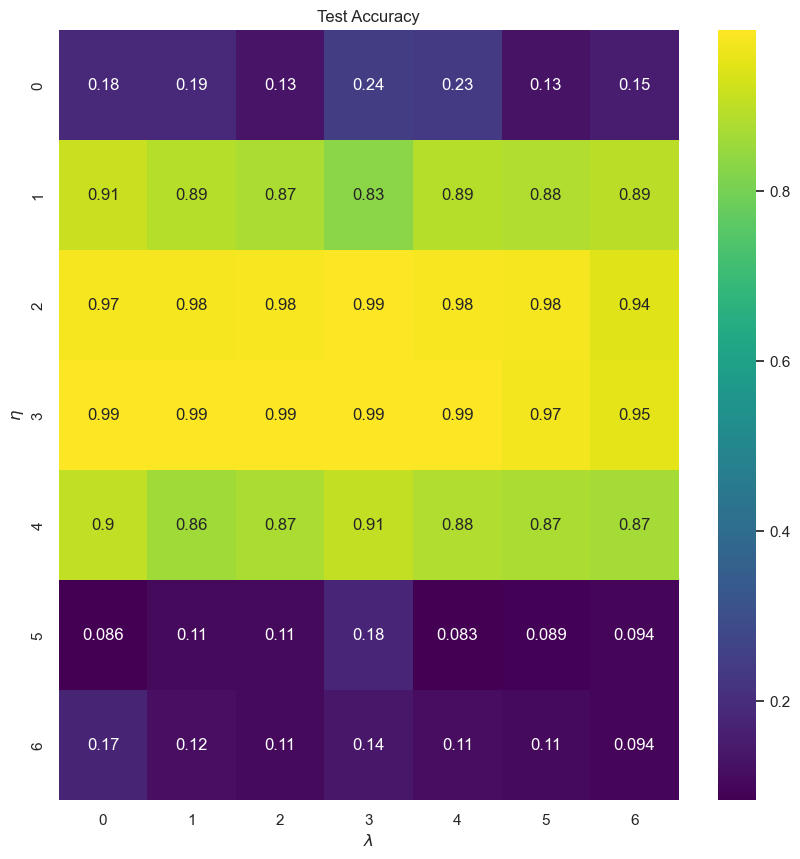
13.7. Building neural networks in Tensorflow and Keras¶
Now we want to build on the experience gained from our neural network implementation in NumPy and scikit-learn and use it to construct a neural network in Tensorflow. Once we have constructed a neural network in NumPy and Tensorflow, building one in Keras is really quite trivial, though the performance may suffer.
In our previous example we used only one hidden layer, and in this we will use two. From this it should be quite clear how to build one using an arbitrary number of hidden layers, using data structures such as Python lists or NumPy arrays.
Tensorflow is an open source library machine learning library developed by the Google Brain team for internal use. It was released under the Apache 2.0 open source license in November 9, 2015.
Tensorflow is a computational framework that allows you to construct machine learning models at different levels of abstraction, from high-level, object-oriented APIs like Keras, down to the C++ kernels that Tensorflow is built upon. The higher levels of abstraction are simpler to use, but less flexible, and our choice of implementation should reflect the problems we are trying to solve.
Tensorflow uses so-called graphs to represent your computation in terms of the dependencies between individual operations, such that you first build a Tensorflow graph to represent your model, and then create a Tensorflow session to run the graph.
In this guide we will analyze the same data as we did in our NumPy and scikit-learn tutorial, gathered from the MNIST database of images. We will give an introduction to the lower level Python Application Program Interfaces (APIs), and see how we use them to build our graph. Then we will build (effectively) the same graph in Keras, to see just how simple solving a machine learning problem can be.
To install tensorflow on Unix/Linux systems, use pip as
pip3 install tensorflow
Input In [13]
pip3 install tensorflow
^
SyntaxError: invalid syntax
and/or if you use anaconda, just write (or install from the graphical user interface) (current release of CPU-only TensorFlow)
conda create -n tf tensorflow
conda activate tf
To install the current release of GPU TensorFlow
conda create -n tf-gpu tensorflow-gpu
conda activate tf-gpu
Keras is a high level neural network
that supports Tensorflow, CTNK and Theano as backends.
If you have Anaconda installed you may run the following command
conda install keras
You can look up the instructions here for more information.
We will to a large extent use keras in this course.
Let us look again at the MINST data set.
# import necessary packages
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn import datasets
# ensure the same random numbers appear every time
np.random.seed(0)
# display images in notebook
%matplotlib inline
plt.rcParams['figure.figsize'] = (12,12)
# download MNIST dataset
digits = datasets.load_digits()
# define inputs and labels
inputs = digits.images
labels = digits.target
print("inputs = (n_inputs, pixel_width, pixel_height) = " + str(inputs.shape))
print("labels = (n_inputs) = " + str(labels.shape))
# flatten the image
# the value -1 means dimension is inferred from the remaining dimensions: 8x8 = 64
n_inputs = len(inputs)
inputs = inputs.reshape(n_inputs, -1)
print("X = (n_inputs, n_features) = " + str(inputs.shape))
# choose some random images to display
indices = np.arange(n_inputs)
random_indices = np.random.choice(indices, size=5)
for i, image in enumerate(digits.images[random_indices]):
plt.subplot(1, 5, i+1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title("Label: %d" % digits.target[random_indices[i]])
plt.show()
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Sequential #This allows appending layers to existing models
from tensorflow.keras.layers import Dense #This allows defining the characteristics of a particular layer
from tensorflow.keras import optimizers #This allows using whichever optimiser we want (sgd,adam,RMSprop)
from tensorflow.keras import regularizers #This allows using whichever regularizer we want (l1,l2,l1_l2)
from tensorflow.keras.utils import to_categorical #This allows using categorical cross entropy as the cost function
from sklearn.model_selection import train_test_split
# one-hot representation of labels
labels = to_categorical(labels)
# split into train and test data
train_size = 0.8
test_size = 1 - train_size
X_train, X_test, Y_train, Y_test = train_test_split(inputs, labels, train_size=train_size,
test_size=test_size)
epochs = 100
batch_size = 100
n_neurons_layer1 = 100
n_neurons_layer2 = 50
n_categories = 10
eta_vals = np.logspace(-5, 1, 7)
lmbd_vals = np.logspace(-5, 1, 7)
def create_neural_network_keras(n_neurons_layer1, n_neurons_layer2, n_categories, eta, lmbd):
model = Sequential()
model.add(Dense(n_neurons_layer1, activation='sigmoid', kernel_regularizer=regularizers.l2(lmbd)))
model.add(Dense(n_neurons_layer2, activation='sigmoid', kernel_regularizer=regularizers.l2(lmbd)))
model.add(Dense(n_categories, activation='softmax'))
sgd = optimizers.SGD(lr=eta)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
DNN_keras = np.zeros((len(eta_vals), len(lmbd_vals)), dtype=object)
for i, eta in enumerate(eta_vals):
for j, lmbd in enumerate(lmbd_vals):
DNN = create_neural_network_keras(n_neurons_layer1, n_neurons_layer2, n_categories,
eta=eta, lmbd=lmbd)
DNN.fit(X_train, Y_train, epochs=epochs, batch_size=batch_size, verbose=0)
scores = DNN.evaluate(X_test, Y_test)
DNN_keras[i][j] = DNN
print("Learning rate = ", eta)
print("Lambda = ", lmbd)
print("Test accuracy: %.3f" % scores[1])
print()
# optional
# visual representation of grid search
# uses seaborn heatmap, could probably do this in matplotlib
import seaborn as sns
sns.set()
train_accuracy = np.zeros((len(eta_vals), len(lmbd_vals)))
test_accuracy = np.zeros((len(eta_vals), len(lmbd_vals)))
for i in range(len(eta_vals)):
for j in range(len(lmbd_vals)):
DNN = DNN_keras[i][j]
train_accuracy[i][j] = DNN.evaluate(X_train, Y_train)[1]
test_accuracy[i][j] = DNN.evaluate(X_test, Y_test)[1]
fig, ax = plt.subplots(figsize = (10, 10))
sns.heatmap(train_accuracy, annot=True, ax=ax, cmap="viridis")
ax.set_title("Training Accuracy")
ax.set_ylabel("$\eta$")
ax.set_xlabel("$\lambda$")
plt.show()
fig, ax = plt.subplots(figsize = (10, 10))
sns.heatmap(test_accuracy, annot=True, ax=ax, cmap="viridis")
ax.set_title("Test Accuracy")
ax.set_ylabel("$\eta$")
ax.set_xlabel("$\lambda$")
plt.show()
13.7.1. The Breast Cancer Data, now with Keras¶
import tensorflow as tf
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Sequential #This allows appending layers to existing models
from tensorflow.keras.layers import Dense #This allows defining the characteristics of a particular layer
from tensorflow.keras import optimizers #This allows using whichever optimiser we want (sgd,adam,RMSprop)
from tensorflow.keras import regularizers #This allows using whichever regularizer we want (l1,l2,l1_l2)
from tensorflow.keras.utils import to_categorical #This allows using categorical cross entropy as the cost function
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split as splitter
from sklearn.datasets import load_breast_cancer
import pickle
import os
"""Load breast cancer dataset"""
np.random.seed(0) #create same seed for random number every time
cancer=load_breast_cancer() #Download breast cancer dataset
inputs=cancer.data #Feature matrix of 569 rows (samples) and 30 columns (parameters)
outputs=cancer.target #Label array of 569 rows (0 for benign and 1 for malignant)
labels=cancer.feature_names[0:30]
print('The content of the breast cancer dataset is:') #Print information about the datasets
print(labels)
print('-------------------------')
print("inputs = " + str(inputs.shape))
print("outputs = " + str(outputs.shape))
print("labels = "+ str(labels.shape))
x=inputs #Reassign the Feature and Label matrices to other variables
y=outputs
#%%
# Visualisation of dataset (for correlation analysis)
plt.figure()
plt.scatter(x[:,0],x[:,2],s=40,c=y,cmap=plt.cm.Spectral)
plt.xlabel('Mean radius',fontweight='bold')
plt.ylabel('Mean perimeter',fontweight='bold')
plt.show()
plt.figure()
plt.scatter(x[:,5],x[:,6],s=40,c=y, cmap=plt.cm.Spectral)
plt.xlabel('Mean compactness',fontweight='bold')
plt.ylabel('Mean concavity',fontweight='bold')
plt.show()
plt.figure()
plt.scatter(x[:,0],x[:,1],s=40,c=y,cmap=plt.cm.Spectral)
plt.xlabel('Mean radius',fontweight='bold')
plt.ylabel('Mean texture',fontweight='bold')
plt.show()
plt.figure()
plt.scatter(x[:,2],x[:,1],s=40,c=y,cmap=plt.cm.Spectral)
plt.xlabel('Mean perimeter',fontweight='bold')
plt.ylabel('Mean compactness',fontweight='bold')
plt.show()
# Generate training and testing datasets
#Select features relevant to classification (texture,perimeter,compactness and symmetery)
#and add to input matrix
temp1=np.reshape(x[:,1],(len(x[:,1]),1))
temp2=np.reshape(x[:,2],(len(x[:,2]),1))
X=np.hstack((temp1,temp2))
temp=np.reshape(x[:,5],(len(x[:,5]),1))
X=np.hstack((X,temp))
temp=np.reshape(x[:,8],(len(x[:,8]),1))
X=np.hstack((X,temp))
X_train,X_test,y_train,y_test=splitter(X,y,test_size=0.1) #Split datasets into training and testing
y_train=to_categorical(y_train) #Convert labels to categorical when using categorical cross entropy
y_test=to_categorical(y_test)
del temp1,temp2,temp
# %%
# Define tunable parameters"
eta=np.logspace(-3,-1,3) #Define vector of learning rates (parameter to SGD optimiser)
lamda=0.01 #Define hyperparameter
n_layers=2 #Define number of hidden layers in the model
n_neuron=np.logspace(0,3,4,dtype=int) #Define number of neurons per layer
epochs=100 #Number of reiterations over the input data
batch_size=100 #Number of samples per gradient update
# %%
"""Define function to return Deep Neural Network model"""
def NN_model(inputsize,n_layers,n_neuron,eta,lamda):
model=Sequential()
for i in range(n_layers): #Run loop to add hidden layers to the model
if (i==0): #First layer requires input dimensions
model.add(Dense(n_neuron,activation='relu',kernel_regularizer=regularizers.l2(lamda),input_dim=inputsize))
else: #Subsequent layers are capable of automatic shape inferencing
model.add(Dense(n_neuron,activation='relu',kernel_regularizer=regularizers.l2(lamda)))
model.add(Dense(2,activation='softmax')) #2 outputs - ordered and disordered (softmax for prob)
sgd=optimizers.SGD(lr=eta)
model.compile(loss='categorical_crossentropy',optimizer=sgd,metrics=['accuracy'])
return model
Train_accuracy=np.zeros((len(n_neuron),len(eta))) #Define matrices to store accuracy scores as a function
Test_accuracy=np.zeros((len(n_neuron),len(eta))) #of learning rate and number of hidden neurons for
for i in range(len(n_neuron)): #run loops over hidden neurons and learning rates to calculate
for j in range(len(eta)): #accuracy scores
DNN_model=NN_model(X_train.shape[1],n_layers,n_neuron[i],eta[j],lamda)
DNN_model.fit(X_train,y_train,epochs=epochs,batch_size=batch_size,verbose=1)
Train_accuracy[i,j]=DNN_model.evaluate(X_train,y_train)[1]
Test_accuracy[i,j]=DNN_model.evaluate(X_test,y_test)[1]
def plot_data(x,y,data,title=None):
# plot results
fontsize=16
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(data, interpolation='nearest', vmin=0, vmax=1)
cbar=fig.colorbar(cax)
cbar.ax.set_ylabel('accuracy (%)',rotation=90,fontsize=fontsize)
cbar.set_ticks([0,.2,.4,0.6,0.8,1.0])
cbar.set_ticklabels(['0%','20%','40%','60%','80%','100%'])
# put text on matrix elements
for i, x_val in enumerate(np.arange(len(x))):
for j, y_val in enumerate(np.arange(len(y))):
c = "${0:.1f}\\%$".format( 100*data[j,i])
ax.text(x_val, y_val, c, va='center', ha='center')
# convert axis vaues to to string labels
x=[str(i) for i in x]
y=[str(i) for i in y]
ax.set_xticklabels(['']+x)
ax.set_yticklabels(['']+y)
ax.set_xlabel('$\\mathrm{learning\\ rate}$',fontsize=fontsize)
ax.set_ylabel('$\\mathrm{hidden\\ neurons}$',fontsize=fontsize)
if title is not None:
ax.set_title(title)
plt.tight_layout()
plt.show()
plot_data(eta,n_neuron,Train_accuracy, 'training')
plot_data(eta,n_neuron,Test_accuracy, 'testing')
13.8. Fine-tuning neural network hyperparameters¶
The flexibility of neural networks is also one of their main drawbacks: there are many hyperparameters to tweak. Not only can you use any imaginable network topology (how neurons/nodes are interconnected), but even in a simple FFNN you can change the number of layers, the number of neurons per layer, the type of activation function to use in each layer, the weight initialization logic, the stochastic gradient optmized and much more. How do you know what combination of hyperparameters is the best for your task?
You can use grid search with cross-validation to find the right hyperparameters.
However,since there are many hyperparameters to tune, and since training a neural network on a large dataset takes a lot of time, you will only be able to explore a tiny part of the hyperparameter space.
You can use randomized search.
Or use tools like Oscar, which implements more complex algorithms to help you find a good set of hyperparameters quickly.
13.8.2. Which activation function should I use?¶
The Back propagation algorithm we derived above works by going from the output layer to the input layer, propagating the error gradient on the way. Once the algorithm has computed the gradient of the cost function with regards to each parameter in the network, it uses these gradients to update each parameter with a Gradient Descent (GD) step.
Unfortunately for us, the gradients often get smaller and smaller as the algorithm progresses down to the first hidden layers. As a result, the GD update leaves the lower layer connection weights virtually unchanged, and training never converges to a good solution. This is known in the literature as the vanishing gradients problem.
In other cases, the opposite can happen, namely the the gradients can grow bigger and bigger. The result is that many of the layers get large updates of the weights the algorithm diverges. This is the exploding gradients problem, which is mostly encountered in recurrent neural networks. More generally, deep neural networks suffer from unstable gradients, different layers may learn at widely different speeds
13.8.3. Is the Logistic activation function (Sigmoid) our choice?¶
Although this unfortunate behavior has been empirically observed for quite a while (it was one of the reasons why deep neural networks were mostly abandoned for a long time), it is only around 2010 that significant progress was made in understanding it.
A paper titled Understanding the Difficulty of Training Deep Feedforward Neural Networks by Xavier Glorot and Yoshua Bengio found that the problems with the popular logistic sigmoid activation function and the weight initialization technique that was most popular at the time, namely random initialization using a normal distribution with a mean of 0 and a standard deviation of 1.
They showed that with this activation function and this initialization scheme, the variance of the outputs of each layer is much greater than the variance of its inputs. Going forward in the network, the variance keeps increasing after each layer until the activation function saturates at the top layers. This is actually made worse by the fact that the logistic function has a mean of 0.5, not 0 (the hyperbolic tangent function has a mean of 0 and behaves slightly better than the logistic function in deep networks).
13.8.4. The derivative of the Logistic funtion¶
Looking at the logistic activation function, when inputs become large (negative or positive), the function saturates at 0 or 1, with a derivative extremely close to 0. Thus when backpropagation kicks in, it has virtually no gradient to propagate back through the network, and what little gradient exists keeps getting diluted as backpropagation progresses down through the top layers, so there is really nothing left for the lower layers.
In their paper, Glorot and Bengio propose a way to significantly alleviate this problem. We need the signal to flow properly in both directions: in the forward direction when making predictions, and in the reverse direction when backpropagating gradients. We don’t want the signal to die out, nor do we want it to explode and saturate. For the signal to flow properly, the authors argue that we need the variance of the outputs of each layer to be equal to the variance of its inputs, and we also need the gradients to have equal variance before and after flowing through a layer in the reverse direction.
One of the insights in the 2010 paper by Glorot and Bengio was that the vanishing/exploding gradients problems were in part due to a poor choice of activation function. Until then most people had assumed that if Nature had chosen to use roughly sigmoid activation functions in biological neurons, they must be an excellent choice. But it turns out that other activation functions behave much better in deep neural networks, in particular the ReLU activation function, mostly because it does not saturate for positive values (and also because it is quite fast to compute).
13.8.5. The RELU function family¶
The ReLU activation function suffers from a problem known as the dying ReLUs: during training, some neurons effectively die, meaning they stop outputting anything other than 0.
In some cases, you may find that half of your network’s neurons are dead, especially if you used a large learning rate. During training, if a neuron’s weights get updated such that the weighted sum of the neuron’s inputs is negative, it will start outputting 0. When this happen, the neuron is unlikely to come back to life since the gradient of the ReLU function is 0 when its input is negative.
To solve this problem, nowadays practitioners use a variant of the ReLU function, such as the leaky ReLU discussed above or the so-called exponential linear unit (ELU) function
13.8.6. Which activation function should we use?¶
In general it seems that the ELU activation function is better than the leaky ReLU function (and its variants), which is better than ReLU. ReLU performs better than \(\tanh\) which in turn performs better than the logistic function.
If runtime performance is an issue, then you may opt for the leaky ReLU function over the ELU function If you don’t want to tweak yet another hyperparameter, you may just use the default \(\alpha\) of \(0.01\) for the leaky ReLU, and \(1\) for ELU. If you have spare time and computing power, you can use cross-validation or bootstrap to evaluate other activation functions.
In most cases you can use the ReLU activation function in the hidden layers (or one of its variants).
It is a bit faster to compute than other activation functions, and the gradient descent optimization does in general not get stuck.
For the output layer:
For classification the softmax activation function is generally a good choice for classification tasks (when the classes are mutually exclusive).
For regression tasks, you can simply use no activation function at all.
13.8.7. Batch Normalization¶
Batch Normalization aims to address the vanishing/exploding gradients problems, and more generally the problem that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change.
The technique consists of adding an operation in the model just before the activation function of each layer, simply zero-centering and normalizing the inputs, then scaling and shifting the result using two new parameters per layer (one for scaling, the other for shifting). In other words, this operation lets the model learn the optimal scale and mean of the inputs for each layer. In order to zero-center and normalize the inputs, the algorithm needs to estimate the inputs’ mean and standard deviation. It does so by evaluating the mean and standard deviation of the inputs over the current mini-batch, from this the name batch normalization.
13.8.8. Dropout¶
It is a fairly simple algorithm: at every training step, every neuron (including the input neurons but excluding the output neurons) has a probability \(p\) of being temporarily dropped out, meaning it will be entirely ignored during this training step, but it may be active during the next step.
The hyperparameter \(p\) is called the dropout rate, and it is typically set to 50%. After training, the neurons are not dropped anymore. It is viewed as one of the most popular regularization techniques.
13.8.9. Gradient Clipping¶
A popular technique to lessen the exploding gradients problem is to simply clip the gradients during backpropagation so that they never exceed some threshold (this is mostly useful for recurrent neural networks).
This technique is called Gradient Clipping.
In general however, Batch Normalization is preferred.
13.9. A top-down perspective on Neural networks¶
The first thing we would like to do is divide the data into two or three parts. A training set, a validation or dev (development) set, and a test set. The test set is the data on which we want to make predictions. The dev set is a subset of the training data we use to check how well we are doing out-of-sample, after training the model on the training dataset. We use the validation error as a proxy for the test error in order to make tweaks to our model. It is crucial that we do not use any of the test data to train the algorithm. This is a cardinal sin in ML. Then:
Estimate optimal error rate
Minimize underfitting (bias) on training data set.
Make sure you are not overfitting.
If the validation and test sets are drawn from the same distributions, then a good performance on the validation set should lead to similarly good performance on the test set.
However, sometimes the training data and test data differ in subtle ways because, for example, they are collected using slightly different methods, or because it is cheaper to collect data in one way versus another. In this case, there can be a mismatch between the training and test data. This can lead to the neural network overfitting these small differences between the test and training sets, and a poor performance on the test set despite having a good performance on the validation set. To rectify this, Andrew Ng suggests making two validation or dev sets, one constructed from the training data and one constructed from the test data. The difference between the performance of the algorithm on these two validation sets quantifies the train-test mismatch. This can serve as another important diagnostic when using DNNs for supervised learning.
13.9.1. Limitations of supervised learning with deep networks¶
Like all statistical methods, supervised learning using neural networks has important limitations. This is especially important when one seeks to apply these methods, especially to physics problems. Like all tools, DNNs are not a universal solution. Often, the same or better performance on a task can be achieved by using a few hand-engineered features (or even a collection of random features).
Here we list some of the important limitations of supervised neural network based models.
Need labeled data. All supervised learning methods, DNNs for supervised learning require labeled data. Often, labeled data is harder to acquire than unlabeled data (e.g. one must pay for human experts to label images).
Supervised neural networks are extremely data intensive. DNNs are data hungry. They perform best when data is plentiful. This is doubly so for supervised methods where the data must also be labeled. The utility of DNNs is extremely limited if data is hard to acquire or the datasets are small (hundreds to a few thousand samples). In this case, the performance of other methods that utilize hand-engineered features can exceed that of DNNs.
Homogeneous data. Almost all DNNs deal with homogeneous data of one type. It is very hard to design architectures that mix and match data types (i.e. some continuous variables, some discrete variables, some time series). In applications beyond images, video, and language, this is often what is required. In contrast, ensemble models like random forests or gradient-boosted trees have no difficulty handling mixed data types.
Many problems are not about prediction. In natural science we are often interested in learning something about the underlying distribution that generates the data. In this case, it is often difficult to cast these ideas in a supervised learning setting. While the problems are related, it is possible to make good predictions with a wrong model. The model might or might not be useful for understanding the underlying science.
Some of these remarks are particular to DNNs, others are shared by all supervised learning methods. This motivates the use of unsupervised methods which in part circumvent these problems.