Week 44, Solving differential equations with neural networks and start Convolutional Neural Networks (CNN)
Contents
Plan for week 44
Lab sessions on Tuesday and Wednesday
Material for Lecture Monday October 27
Solving differential equations with Deep Learning
Ordinary Differential Equations first
The trial solution
Minimization process
Minimizing the cost function using gradient descent and automatic differentiation
Example: Exponential decay
The function to solve for
The trial solution
Setup of Network
Reformulating the problem
More technicalities
More details
A possible implementation of a neural network
Technicalities
Final technicalities I
Final technicalities II
Final technicalities III
Final technicalities IV
Back propagation
Gradient descent
The code for solving the ODE
The network with one input layer, specified number of hidden layers, and one output layer
Example: Population growth
Setting up the problem
The trial solution
The program using Autograd
Using forward Euler to solve the ODE
Example: Solving the one dimensional Poisson equation
The specific equation to solve for
Solving the equation using Autograd
Comparing with a numerical scheme
Setting up the code
Partial Differential Equations
Type of problem
Network requirements
More details
Example: The diffusion equation
Defining the problem
Setting up the network using Autograd
Setting up the network using Autograd; The trial solution
Why the Jacobian?
Setting up the network using Autograd; The full program
Resources on differential equations and deep learning
Convolutional Neural Networks (recognizing images)
What is the Difference
Neural Networks vs CNNs
Why CNNS for images, sound files, medical images from CT scans etc?
Regular NNs don’t scale well to full images
3D volumes of neurons
More on Dimensionalities
Further remarks
Layers used to build CNNs
Transforming images
CNNs in brief
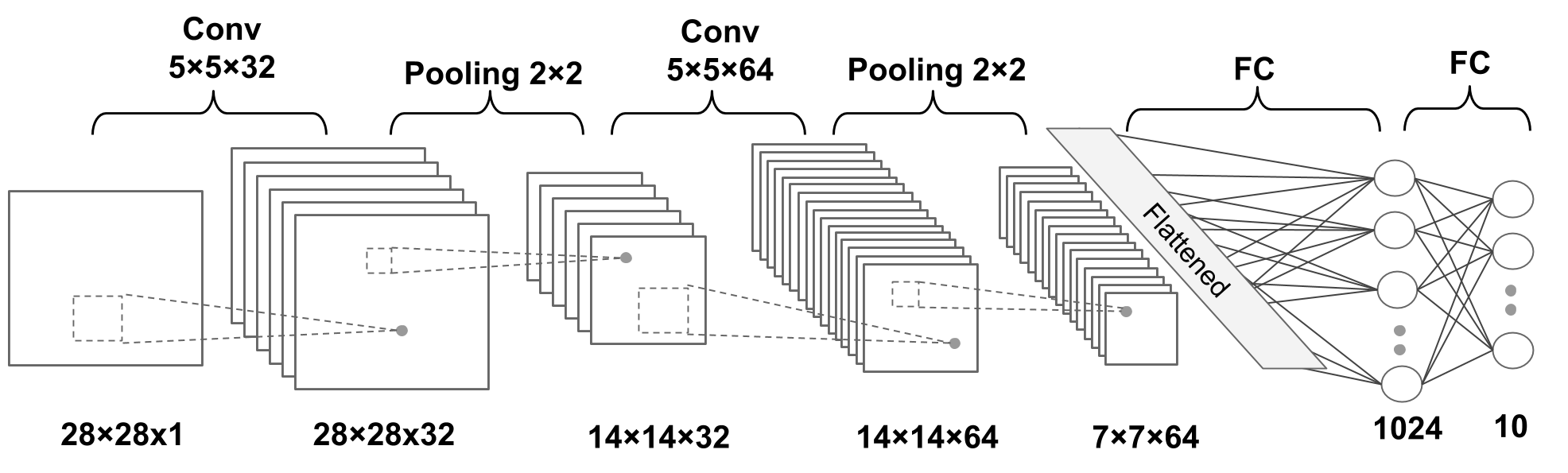
A deep CNN model ("From Raschka et al":"https://github.com/rasbt/machine-learning-book")
Key Idea
How to do image compression before the era of deep learning
The SVD example
Mathematics of CNNs
Convolution Examples: Polynomial multiplication
Efficient Polynomial Multiplication
Further simplification
A more efficient way of coding the above Convolution
Commutative process
Toeplitz matrices
Fourier series and Toeplitz matrices
Generalizing the above one-dimensional case
Memory considerations
Padding
New vector
Rewriting as dot products
Cross correlation
Two-dimensional objects
CNNs in more detail, simple example
The convolution stage
Finding the number of parameters
New image (or volume)
Parameters to train, common settings
Examples of CNN setups
Summarizing: Performing a general discrete convolution ("From Raschka et al":"https://github.com/rasbt/machine-learning-book")
Pooling
Pooling arithmetic
Pooling types ("From Raschka et al":"https://github.com/rasbt/machine-learning-book")
Building convolutional neural networks in Tensorflow/Keras and PyTorch
A deep CNN model (
From Raschka et al
)
Figure 3: A deep CNN
«
1
...
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
...
87
»